Claude Opus 4.6 vs GPT-5.3 Codex : Quel modèle IA de codage
By Dorian Laurenceau
Claude Opus 4.6 vs GPT-5.3 Codex : Quel modèle IA de codage l'emporte en 2026 ?
📅 Dernière révision : 24 avril 2026. Mise à jour avec les retours et observations d'avril 2026.
📚 Articles liés : Guide Claude Opus 4.6 | Guide GPT-5.3 Codex | Benchmarks LLM 2026 | Comparaison des éditeurs de code IA
Le 5 février 2026 a été une journée historique pour l'IA : Anthropic et OpenAI ont tous deux lancé leurs modèles les plus puissants simultanément. Claude Opus 4.6 a apporté une fenêtre de contexte de 1 million de tokens et la pensée adaptative. GPT-5.3-Codex a introduit la première classification « High » en cybersécurité et l'auto-amorçage.
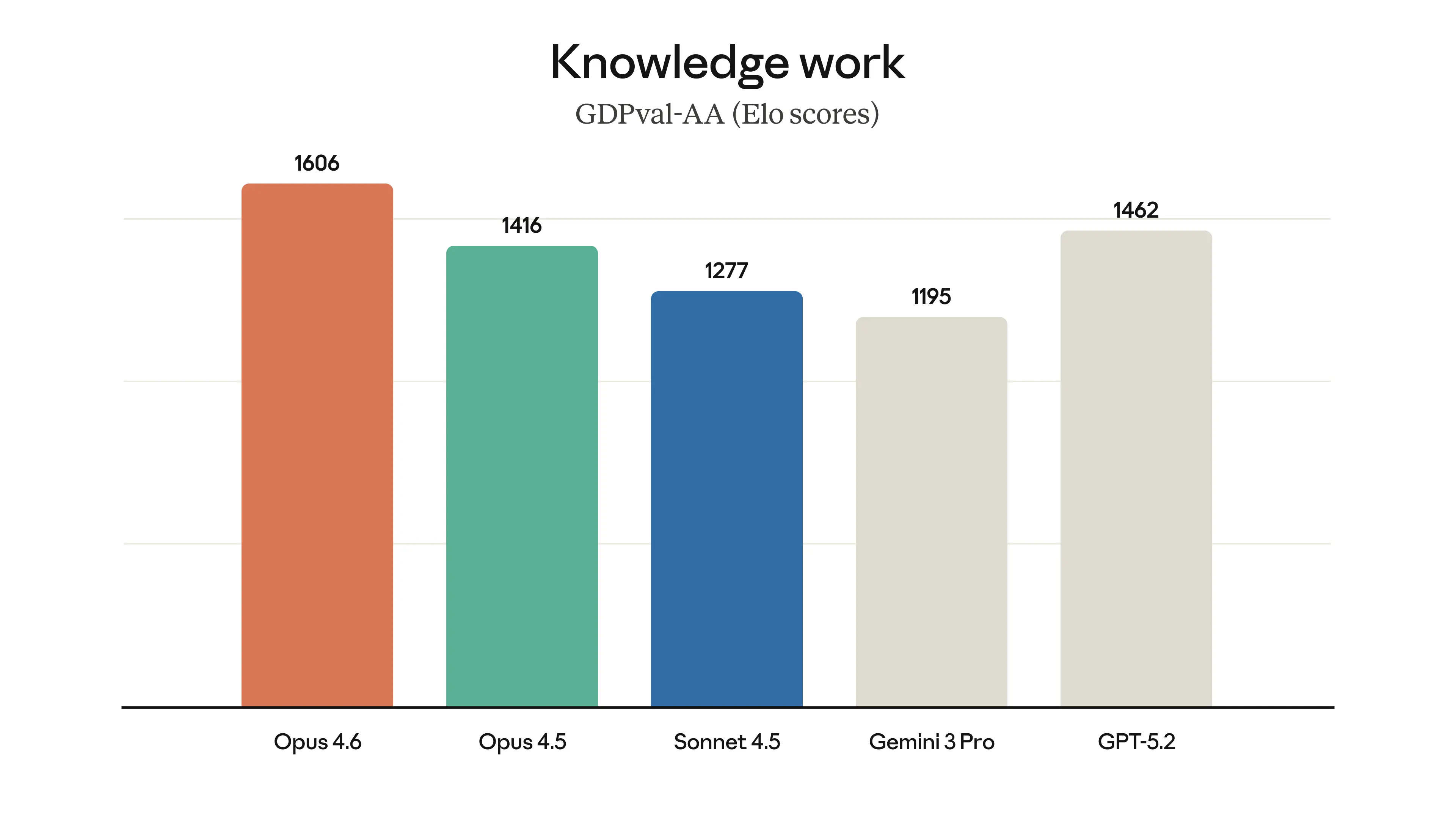 Résultats benchmark GDPval-AA de Claude Opus 4.6, Source : Anthropic
Résultats benchmark GDPval-AA de Claude Opus 4.6, Source : Anthropic
 GPT-5.3-Codex effectuant une tâche de travail intellectuel GDPval, Source : OpenAI
GPT-5.3-Codex effectuant une tâche de travail intellectuel GDPval, Source : OpenAI
Mais lequel devriez-vous réellement utiliser ? La réponse dépend entièrement de votre cas d'usage. Dans cette comparaison basée sur les données, nous analyserons chaque dimension qui compte, avec des scores de benchmark, des tableaux de fonctionnalités et des verdicts clairs pour chaque scénario.
Les concurrents
Le cadre honnête pour toute comparaison « Claude vs GPT » en 2026, tel que le documentent les mégathreads en cours sur r/ChatGPTCoding, r/OpenAI, et r/ClaudeAI : les benchmarks sont assez proches pour que le choix de modèle se joue généralement sur les modes d'échec tolérables, pas sur les scores absolus. Opus 4.6 tend à être plus délibéré et plus prêt à dire « je ne sais pas » ; GPT-5.3 Codex tend à produire plus de code plus vite avec plus d'assurance. Les deux ont raison la plupart du temps, tort différemment, et s'améliorent mois après mois. Les trois benchmarks qui méritent un suivi sont LMArena, LiveBench, et SWE-Bench Verified ; la plupart des autres sont saturés.
Là où la communauté nuance à juste titre les posts de comparaison : votre charge de travail n'est pas le benchmark. Un modèle qui gagne sur HumanEval de trois points peut quand même être pire pour votre codebase s'il ne correspond pas à votre style, à votre framework ou à votre culture de review. Les équipes qui migrent entre modèles frontières à chaque lancement découvrent typiquement que le vrai coût, c'est la réécriture de prompts, la reconstruction d'évaluations et l'invalidation de cache — souvent plusieurs semaines d'ingénierie pour récupérer la productivité pré-migration.
Règle pragmatique : choisissez un modèle frontière comme daily driver, gardez un second dispo pour des checks A/B sur prompts difficiles, et réévaluez sérieusement (avec votre propre eval set, pas Twitter) une fois par trimestre. Plus fréquent que ça, c'est de l'agitation, pas de l'optimisation.
Comparaison benchmark
Comparons les chiffres concrets. Note : ces modèles utilisent des suites de benchmark différentes, rendant la comparaison directe difficile. Nous présentons ce qui est disponible pour chacun.
Benchmarks de codage
Benchmarks de raisonnement et généraux
La réalité des benchmarks
Trois observations importantes :
- →Des suites d'évaluation différentes rendent la comparaison pommes-pommes impossible pour la plupart des benchmarks
- →Terminal-Bench 2.0 est le seul benchmark où les deux modèles revendiquent les meilleures performances, mais Anthropic n'a pas publié de chiffre exact pour Opus 4.6
- →Claude Opus 4.6 a beaucoup plus de données de benchmark publiées que GPT-5.3-Codex, ce qui est typique des system cards détaillées d'Anthropic vs la divulgation plus sélective d'OpenAI
Codage agentique
Les deux modèles sont conçus pour des tâches de codage autonomes et multi-étapes, mais ils l'abordent très différemment.
Claude Opus 4.6 : Équipes d'agents + Contexte 1M
L'approche de codage d'Opus 4.6 est centrée sur l'ampleur et le parallélisme :
- →Équipes d'agents (aperçu recherche) : Lancez plusieurs agents Claude Code travaillant en parallèle sur la même base de code
- →Contexte de 1M de tokens : Comprenez des bases de code entières de taille moyenne à grande en une seule session
- →Compaction de contexte : Résumez automatiquement le contexte ancien pour prolonger la durée de session
- →Planification soigneuse : Crée des plans d'exécution détaillés avant de faire des modifications
Idéal pour : Grandes bases de code, refactoring architectural, projets multi-jours nécessitant une compréhension approfondie du système entier.
GPT-5.3-Codex : Vitesse + Collaboration interactive
L'approche de GPT-5.3-Codex est centrée sur la vitesse et l'interactivité :
- →25 % plus rapide que son prédécesseur avec moins de tokens par tâche
- →Mises à jour interactives : Fournit des rapports de progression et permet le pilotage pendant l'exécution
- →Projets autonomes multi-jours : Peut travailler sur des applications complexes pendant des jours
- →Auto-correction : Entraîné à identifier et corriger ses propres bugs
Idéal pour : Développement greenfield, prototypage rapide, projets où la collaboration en temps réel est valorisée.
Contexte long
C'est ici que les modèles divergent le plus dramatiquement.
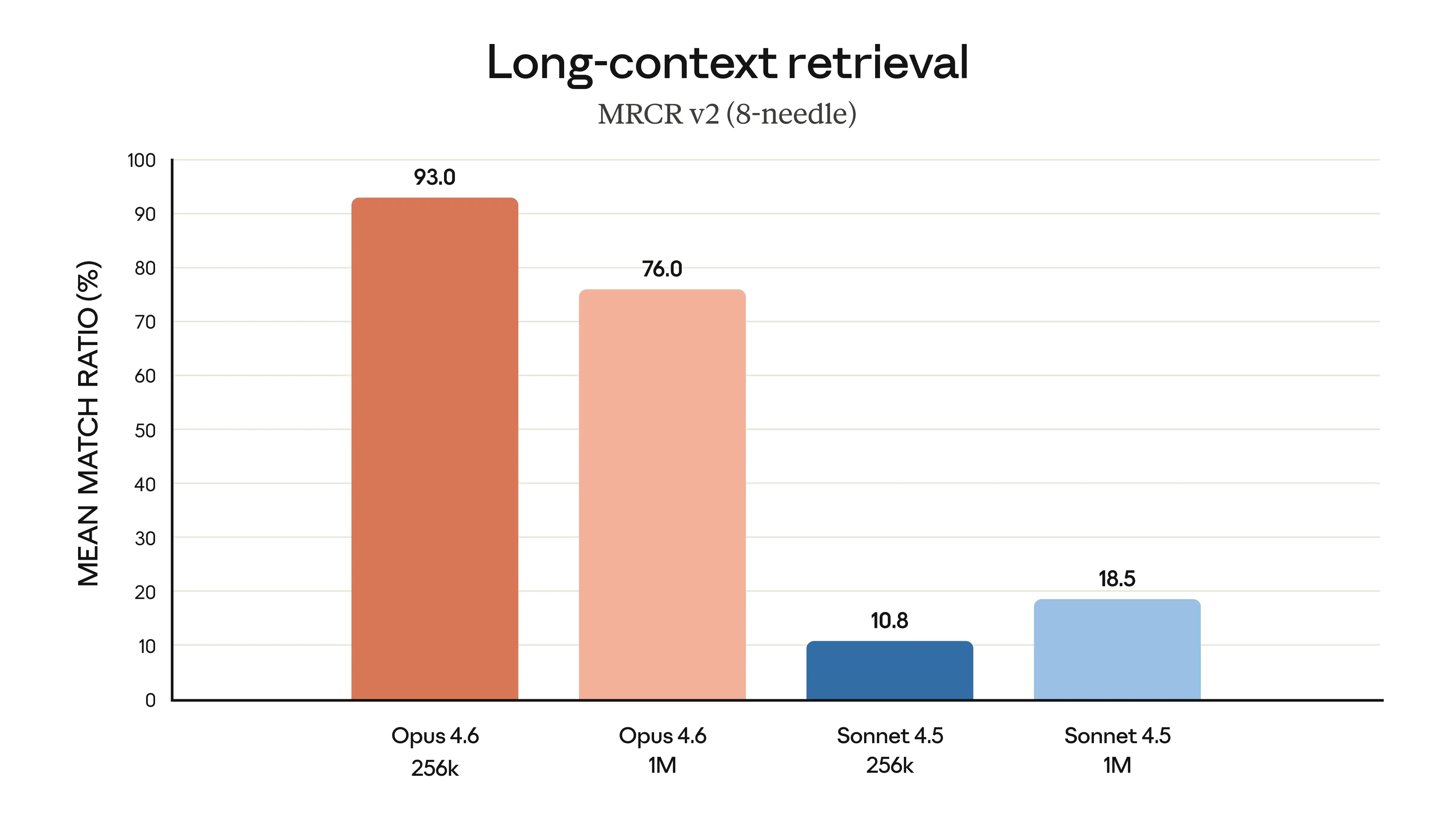 Claude Opus 4.6 montre une amélioration significative de la récupération en contexte long, Source : Anthropic
Claude Opus 4.6 montre une amélioration significative de la récupération en contexte long, Source : Anthropic
Verdict : Claude Opus 4.6 l'emporte nettement. Avec une fenêtre de contexte vérifiée de 1M et 76 % de récupération MRCR, Opus 4.6 établit un nouveau standard pour l'IA en contexte long. GPT-5.3-Codex n'a pas divulgué la taille de sa fenêtre de contexte, rendant la comparaison impossible, mais la transparence d'Opus 4.6 ici est en soi un avantage.
Cybersécurité
Les deux modèles revendiquent des capacités exceptionnelles en cybersécurité, mais avec des approches fondamentalement différentes.
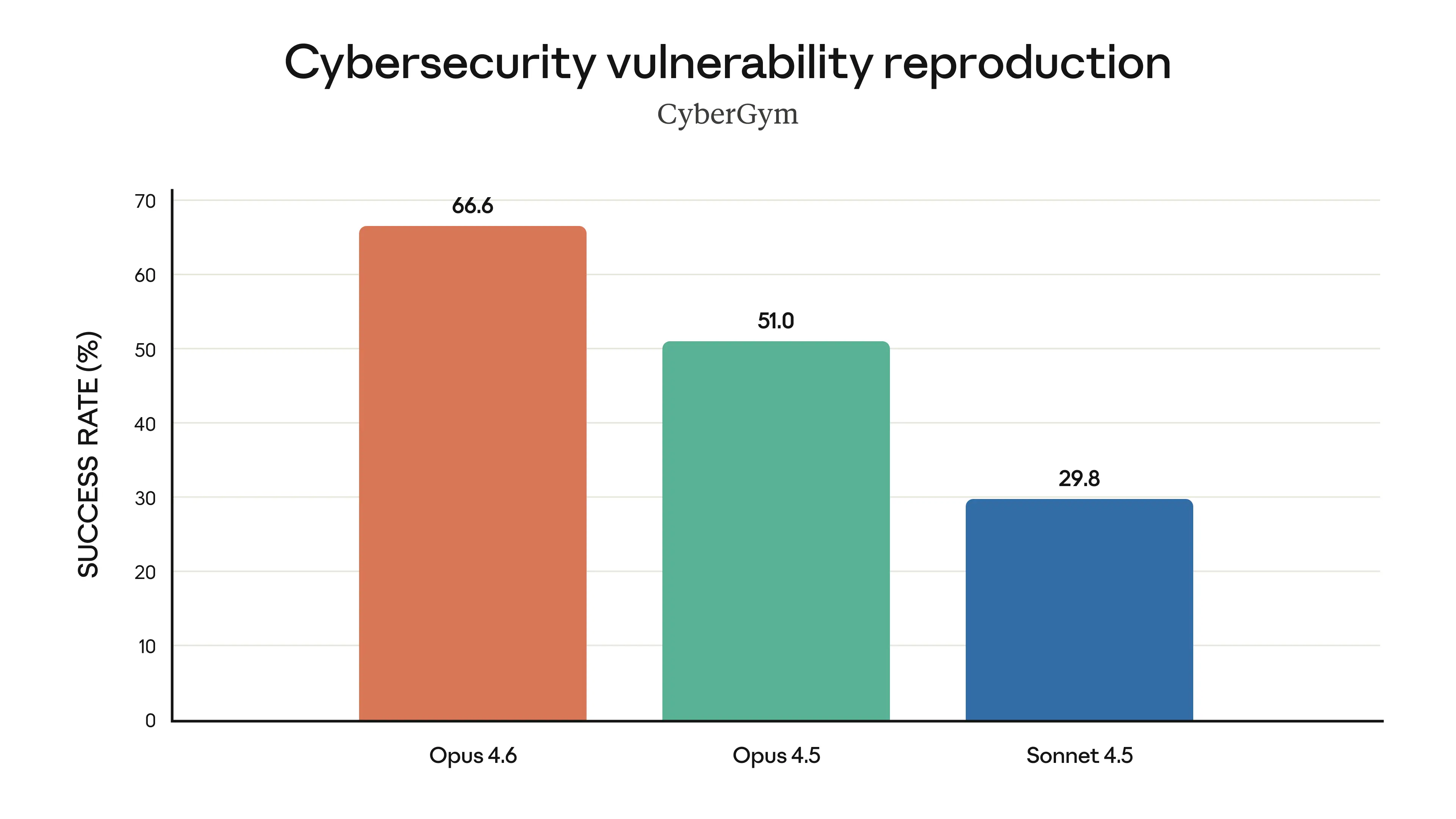 Benchmark CyberGym de Claude Opus 4.6 : trouve des vulnérabilités réelles mieux que tout autre modèle, Source : Anthropic
Benchmark CyberGym de Claude Opus 4.6 : trouve des vulnérabilités réelles mieux que tout autre modèle, Source : Anthropic
Tarifs et disponibilité
C'est peut-être la différence pratique la plus importante entre les deux modèles.
Verdict : Claude Opus 4.6 l'emporte sur l'accessibilité. Accès API complet avec tarification transparente (5 $/25 $ par million de tokens) dès le premier jour, disponible sur les trois principaux fournisseurs cloud. L'absence d'accès API de GPT-5.3-Codex est une limitation significative pour tout cas d'usage au-delà du codage personnel.
Écosystème
Différence clé : Claude Opus 4.6 bénéficie de l'écosystème Model Context Protocol (MCP) d'Anthropic, permettant l'intégration avec des outils externes, des bases de données et des services. GPT-5.3-Codex opère dans l'écosystème plus fermé d'OpenAI.
Verdict par cas d'usage
Voici le résultat final, quel modèle utiliser pour chaque scénario :
La vision d'ensemble
Question de coûts
Estimation du coût de Claude Opus 4.6
Pour une session de codage typique (50K tokens en entrée, 10K tokens en sortie) :
- →Standard : 0,25 $ entrée + 0,25 $ sortie = 0,50 $ par session
- →Contexte 1M : 0,50 $ entrée + 0,375 $ sortie = 0,875 $ par session
Estimation du coût de GPT-5.3-Codex
- →App Codex : Incluse dans ChatGPT Plus (20 $/mois), illimité dans le cadre d'un usage raisonnable
- →API : Non disponible, aucune estimation de coût par token possible
Pour un usage intensif (50+ sessions/jour), les coûts API d'Opus 4.6 peuvent s'accumuler rapidement. Le modèle d'abonnement ChatGPT avec Codex peut être plus rentable pour un usage personnel, mais ne peut pas être intégré dans des produits.
La vision globale : Paysage IA de février 2026
Ces deux sorties confirment une tendance claire de l'industrie : la spécialisation.
- →OpenAI construit des modèles spécialisés pour des domaines spécifiques (Codex pour le codage, futures variantes pour d'autres domaines)
- →Anthropic construit des modèles de pointe polyvalents qui excellent dans tous les domaines tout en maintenant une seule ligne de modèles
Cette différence philosophique façonne tout :
- →L'approche d'OpenAI : « Utilisez le bon outil pour le travail » (GPT-5.2 pour le général, Codex pour le codage)
- →L'approche d'Anthropic : « Un modèle pour les gouverner tous » (Opus 4.6 fait tout)
Aucune approche n'est intrinsèquement meilleure. Mais pour les développeurs et les entreprises, le modèle unifié d'Anthropic simplifie l'architecture, une seule API, une seule facturation, une seule intégration pour toutes les tâches.
Testez vos connaissances
FAQ
Quel modèle est meilleur pour les débutants ?
Pour les débutants, GPT-5.3-Codex via l'app Codex est plus accessible, il fournit des conseils interactifs, des mises à jour de progression et ne nécessite pas de connaissances API. Claude Opus 4.6 via claude.ai est également accessible aux débutants mais ressemble davantage à une interface de chat traditionnelle.
Puis-je utiliser les deux modèles ensemble ?
Oui, et c'est recommandé pour les flux de travail professionnels. Utilisez Claude Opus 4.6 comme modèle principal (accès API, polyvalence, contexte 1M) et GPT-5.3-Codex via l'app Codex pour les sprints de codage spécialisés, les audits de sécurité et le prototypage rapide.
GPT-5.3-Codex aura-t-il un accès API ?
OpenAI a confirmé qu'ils « travaillent à activer en toute sécurité » l'accès API. Étant donné la classification « High » en cybersécurité du modèle, des mesures de sécurité supplémentaires sont probablement nécessaires avant un accès programmatique large. Aucun calendrier n'a été annoncé.
Comment se comparent-ils à Gemini ?
Le Gemini 3 Pro de Google offre une fenêtre de contexte de 2M+ tokens (plus grande que les deux), mais est généralement en retard derrière Opus 4.6 et GPT-5.3-Codex sur les benchmarks de codage. Gemini excelle pour le traitement massif de documents et l'intégration Google Workspace.
Quel modèle s'améliore le plus vite ?
D'après les tendances historiques : OpenAI publie des mises à jour spécialisées de Codex plus fréquemment (tous les 1-2 mois). Anthropic publie des mises à jour majeures d'Opus tous les 3-4 mois mais avec des progrès plus importants. Les deux s'améliorent rapidement.
- →Guide GPT-5.3 Codex, Analyse complète de GPT-5.3-Codex
- →Guide Claude Opus 4.5, Modèle précédent d'Anthropic
- →GPT-5.2 Codex Deep Dive, Modèle de codage précédent d'OpenAI
- →Benchmarks LLM 2026, Comparaison complète des modèles
- →Comparaison des éditeurs de code IA, Benchmarks des IDE et outils
- →Claude Code vs Copilot vs Cursor, Comparaison des outils de codage
Ce qu'il faut retenir
- →
Pas de gagnant universel, GPT-5.3-Codex mène sur le codage spécialisé et l'utilisation de l'ordinateur ; Claude Opus 4.6 mène sur la polyvalence, le raisonnement et le contexte long
- →
L'accès API est la différence pratique décisive, Seul Opus 4.6 en dispose en février 2026
- →
Contexte 1M vs inconnu, Le contexte vérifié de 1M d'Opus 4.6 avec 76 % de récupération est un avantage clair pour le travail à grande échelle
- →
Cybersécurité : les deux excellent différemment, GPT-5.3 est entraîné offensivement ; Opus 4.6 est orienté défensif
- →
Les tarifs favorisent Opus 4.6 pour un accès transparent à l'usage (5 $/25 $ par million de tokens)
- →
Utilisez les deux pour une capacité maximale, Opus pour l'intégration et la polyvalence, Codex pour les sprints de codage spécialisés
- →
La tendance de l'industrie est claire : spécialisation (OpenAI) vs généralisation (Anthropic), votre choix dépend de si vous voulez un seul modèle ou le meilleur outil pour chaque tâche
Comprendre l'évaluation des modèles IA et la sélection
Choisir entre des modèles IA de pointe nécessite de comprendre les benchmarks, les limitations et les performances en conditions réelles. L'approche basée sur les données de cet article reflète les compétences analytiques que vous développerez dans nos modules avancés.
Dans notre Module 8, Éthique et sécurité de l'IA, vous apprendrez :
- →Comment évaluer les modèles IA au-delà des benchmarks marketing
- →Comprendre les risques de double usage en cybersécurité IA
- →Construire des stratégies de déploiement IA responsables
- →Détection et atténuation des biais à travers les modèles
- →Quand faire confiance au code généré par l'IA en production
Module 8 — Ethics, Security & Compliance
Navigate AI risks, prompt injection, and responsible usage.
Dorian Laurenceau
Full-Stack Developer & Learning DesignerFull-stack web developer and learning designer. I spent 4 years as a freelance full-stack developer and 4 years teaching React, JavaScript, HTML/CSS and WordPress to adult learners. Today I design learning paths in web development and AI, grounded in learning science. I founded learn-prompting.fr to make AI practical and accessible, and built the Bluff app to gamify political transparency.
Weekly AI Insights
Tools, techniques & news — curated for AI practitioners. Free, no spam.
Free, no spam. Unsubscribe anytime.
→Related Articles
FAQ
Lequel est meilleur, Claude Opus 4.6 ou GPT-5.3-Codex ?+
Aucun n'est universellement meilleur. GPT-5.3-Codex mène sur Terminal-Bench 2.0 (77,3 %) et OSWorld (64,7 %) pour le codage pur et l'utilisation de l'ordinateur. Claude Opus 4.6 mène sur le raisonnement général, offre un contexte de 1M de tokens, dispose d'un accès API et est plus polyvalent pour le travail intellectuel.
Quel modèle est meilleur pour le codage en 2026 ?+
Pour les tâches de codage agentique pur, GPT-5.3-Codex obtient un score plus élevé sur Terminal-Bench 2.0 (77,3 % vs le classement N°1 d'Opus 4.6). Pour l'ingénierie logicielle plus large incluant les décisions d'architecture et le travail en contexte long, le contexte de 1M d'Opus 4.6 et ses équipes d'agents lui donnent un avantage.
Combien coûtent Claude Opus 4.6 et GPT-5.3 ?+
Claude Opus 4.6 : 5 $/25 $ par million de tokens en entrée/sortie via API. GPT-5.3-Codex : pas de tarif API disponible, accessible uniquement via les plans payants ChatGPT (20-200 $/mois) et les outils Codex.
Puis-je utiliser Claude Opus 4.6 et GPT-5.3 via API ?+
Claude Opus 4.6 a un accès API complet dès le premier jour (API Anthropic, AWS Bedrock, Google Vertex AI). GPT-5.3-Codex n'a PAS encore d'accès API, OpenAI « travaille à l'activer en toute sécurité ».
Quel modèle est plus sûr pour le travail en cybersécurité ?+
GPT-5.3-Codex est le premier modèle IA classé « High » en cybersécurité et est entraîné à trouver des vulnérabilités. Claude Opus 4.6 a remporté 38/40 investigations en cybersécurité. Les deux excellent mais avec des approches différentes : GPT est orienté offensif, Claude est orienté défensif.
Devrais-je utiliser Claude Opus 4.6 ou GPT-5.3 pour ma startup ?+
Pour les startups, Claude Opus 4.6 est plus pratique aujourd'hui : accès API pour l'intégration produit, tarification transparente (5 $/25 $), contexte de 1M pour les grandes bases de code et équipes d'agents pour le développement parallèle. GPT-5.3-Codex n'a pas d'accès API, limitant les options d'intégration.