Claude Opus 4.6 : Guide complet, Contexte 1M
By Dorian Laurenceau
Claude Opus 4.6 : Guide complet, Contexte 1M, Pensée adaptative et benchmarks (2026)
📅 Dernière révision : 24 avril 2026. Mise à jour avec les retours et observations d'avril 2026.
📚 Articles liés : Guide Claude Opus 4.5 | Guide Claude Cowork | Opus 4.6 vs GPT-5.3 Codex | Benchmarks LLM 2026
📺 Vidéo d'annonce officielle
Source : YouTube Anthropic, Annonce officielle, 5 février 2026.
Sommaire
- →Qu'est-ce que Claude Opus 4.6 ?
- →Spécifications techniques
- →Nouveautés par rapport à Opus 4.5
- →Performances benchmark
- →Fonctionnalités clés en détail
- →Tarifs et disponibilité
- →Comment utiliser Opus 4.6
- →Cas d'usage et recommandations
- →Sécurité et alignement
- →FAQ
Le 5 février 2026, Anthropic a lancé Claude Opus 4.6, son modèle IA le plus performant à ce jour. Opus 4.6 représente un bond qualitatif dans trois domaines critiques : il introduit une fenêtre de contexte de 1 million de tokens (le premier modèle de classe Opus avec cette capacité), une pensée adaptative qui ajuste automatiquement la profondeur du raisonnement, et des performances de codage agentique de pointe qui surpassent tous les concurrents sur Terminal-Bench 2.0.
Ce n'est pas une mise à jour incrémentale. Opus 4.6 redéfinit ce qui est possible avec l'IA en contexte long : son score MRCR v2 de 76 % sur la récupération 8-aiguilles 1M écrase les 18,5 % de Sonnet 4.5, ce qui signifie qu'il peut véritablement travailler avec des documents massifs, des bases de code et des corpus de recherche sans perdre d'information. Combiné à une réduction de prix de 67 % sur les tokens en entrée par rapport à Opus 4.5, ce modèle rend les capacités de pointe accessibles à une fraction du coût précédent.
Dans ce guide complet, nous détaillerons l'architecture d'Opus 4.6, ses résultats de benchmark, ses nouvelles fonctionnalités, ses tarifs et ses cas d'usage pratiques, tout ce dont vous avez besoin pour décider si et comment l'intégrer dans votre flux de travail.
Qu'est-ce que Claude Opus 4.6 ?
Claude Opus 4.6 est le modèle IA phare d'Anthropic, conçu pour les tâches les plus exigeantes en codage, raisonnement, analyse et travail intellectuel. C'est le successeur de Claude Opus 4.5, sorti trois mois plus tôt, et représente la mise à niveau de modèle la plus significative d'Anthropic du cycle 2025-2026.
Définition clé : Claude Opus 4.6 est un grand modèle de langage de pointe avec une fenêtre de contexte de 1M de tokens, un raisonnement adaptatif et les meilleurs scores sur les benchmarks de codage agentique et de récupération en contexte long en date de février 2026. Il est disponible via API, Claude.ai, AWS Bedrock et Google Vertex AI.
Ce qui rend Opus 4.6 différent ?
Contrairement aux modèles traditionnels qui traitent chaque requête avec la même profondeur de raisonnement, Opus 4.6 introduit la pensée adaptative, le modèle lui-même décide quand un problème nécessite un raisonnement en chaîne de pensée approfondi et quand une réponse rapide suffit. Cela élimine le besoin pour les utilisateurs de définir manuellement les niveaux « d'effort de réflexion », produisant des réponses plus rapides pour les tâches simples et des analyses plus approfondies pour les tâches complexes.
La lecture honnête d'Opus 4.6 après deux semaines d'usage réel, remontée sur r/ClaudeAI, r/LocalLLaMA, et r/ChatGPTCoding : le cadre « pensée adaptative » est du vocabulaire marketing pour ce que la communauté recherche appelle depuis deux ans mixture-of-depths et routage — le modèle dépense plus de compute sur les prompts difficiles et moins sur les faciles. C'est une capacité réelle, et des benchmarks comme SWE-Bench Verified et le leaderboard d'Aider placent Opus 4.6 en tête ou près du top, mais le gain pratique est plus étroit que ce que suggère le post de lancement : il est surtout visible sur des tâches de coding agentique multi-heures, beaucoup moins visible sur le Q&R single-turn où l'ancien tier Sonnet suffisait déjà.
Là où la communauté nuance à juste titre : les benchmarks « frontières » saturent vite, et l'écart entre Opus 4.6 et ses concurrents proches (GPT-5.3 Codex, Gemini 3.1 Pro) sur la plupart des charges de production est dans le bruit. Les équipes qui changent de modèle à chaque lancement passent plus de temps à recalibrer prompts et évaluations qu'elles n'en gagnent en qualité. Le leaderboard LMArena et LiveBench sont les bons endroits pour vérifier votre mix de tâches spécifique avant de migrer.
Règle opérationnelle pragmatique : Opus 4.6 justifie son prix premium uniquement si votre travail est agentique, long-contexte ou très codé ; sinon Sonnet à une fraction du coût est le bon défaut, et Haiku est le bon défaut pour le travail de masse haute fréquence.
Spécifications techniques
| Spécification | Claude Opus 4.6 | Claude Opus 4.5 (précédent) |
|---|---|---|
| Identifiant modèle | claude-opus-4-6 | claude-opus-4-5-20250929 |
| Fenêtre de contexte | 1M tokens (bêta) / 200K standard | 200K tokens |
| Sortie maximale | 128K tokens | 32K tokens |
| Pensée étendue | ✅ Oui | ✅ Oui |
| Pensée adaptative | ✅ Nouveau | ❌ Non |
| Niveaux d'effort | low, medium, high (défaut), max | low, medium, high |
| Date de coupure des connaissances | Mai 2025 (fiable) / Août 2025 (entraînement) | Mars 2025 |
| Prix en entrée | 5 $ / M tokens | 15 $ / M tokens |
| Prix en sortie | 25 $ / M tokens | 75 $ / M tokens |
| Prix contexte 1M | 10 $ / 37,50 $ (entrée/sortie) | N/A |
Le changement de tarif est spectaculaire : les tokens en entrée sont 67 % moins chers et les tokens en sortie sont 67 % moins chers qu'Opus 4.5. Cela fait d'Opus 4.6 le modèle de pointe le plus rentable jamais proposé par Anthropic.
Nouveautés par rapport à Opus 4.5
1. Fenêtre de contexte de 1 million de tokens (bêta)
Opus 4.6 est le premier modèle de classe Opus à supporter 1M de tokens de contexte. Les modèles Opus précédents étaient limités à 200K. Cette fonctionnalité bêta s'active automatiquement pour les prompts dépassant 200K tokens, avec un tarif légèrement supérieur (10 $/37,50 $ par million).
Pourquoi c'est important : Avec 1M de tokens, vous pouvez fournir à Opus 4.6 une base de code entière (~50 000 lignes), un ensemble complet de contrats juridiques ou des centaines d'articles de recherche en un seul prompt, et il retiendra et utilisera véritablement cette information. Le benchmark MRCR v2 prouve que ce n'est pas seulement une capacité théorique.
2. Pensée adaptative
Les modèles précédents nécessitaient que les utilisateurs spécifient l'effort de réflexion (low/medium/high). Opus 4.6 introduit un nouveau paradigme : le modèle décide de manière autonome quand un raisonnement plus approfondi est utile.
Comment ça fonctionne :
- →Requêtes factuelles simples → raisonnement interne minimal → réponse rapide
- →Codage ou analyse complexe → chaîne de pensée approfondie → réponse détaillée
- →Problèmes ambigus → raisonnement calibré → réponse équilibrée
Vous pouvez toujours surcharger avec des niveaux d'effort manuels, mais le mode adaptatif par défaut est très efficace. Le niveau d'effort max est nouveau et pousse la profondeur de raisonnement au-delà de ce que high offrait dans Opus 4.5.
3. Compaction de contexte (bêta)
Pour les sessions agentiques de longue durée, Opus 4.6 peut résumer automatiquement le contexte ancien pour prolonger la durée de la tâche sans atteindre les limites de contexte. C'est critique pour les agents de codage qui doivent travailler sur des projets pendant des heures, pas des minutes.
4. Équipes d'agents (aperçu recherche)
Plusieurs agents Claude Code peuvent désormais travailler en parallèle sur la même base de code, chacun gérant des sous-tâches indépendantes. Pensez-y comme du pair programming parallélisé, un agent gère le frontend, un autre le backend, un troisième écrit les tests.
5. Réduction massive des prix
| Métrique | Opus 4.5 | Opus 4.6 | Changement |
|---|---|---|---|
| Entrée | 15 $/M | 5 $/M | -67 % |
| Sortie | 75 $/M | 25 $/M | -67 % |
Cela rend Opus 4.6 moins cher que de nombreux modèles de milieu de gamme tout en offrant des performances de pointe.
Performances benchmark
Opus 4.6 obtient des résultats de pointe sur de multiples benchmarks. Voici les scores vérifiés :
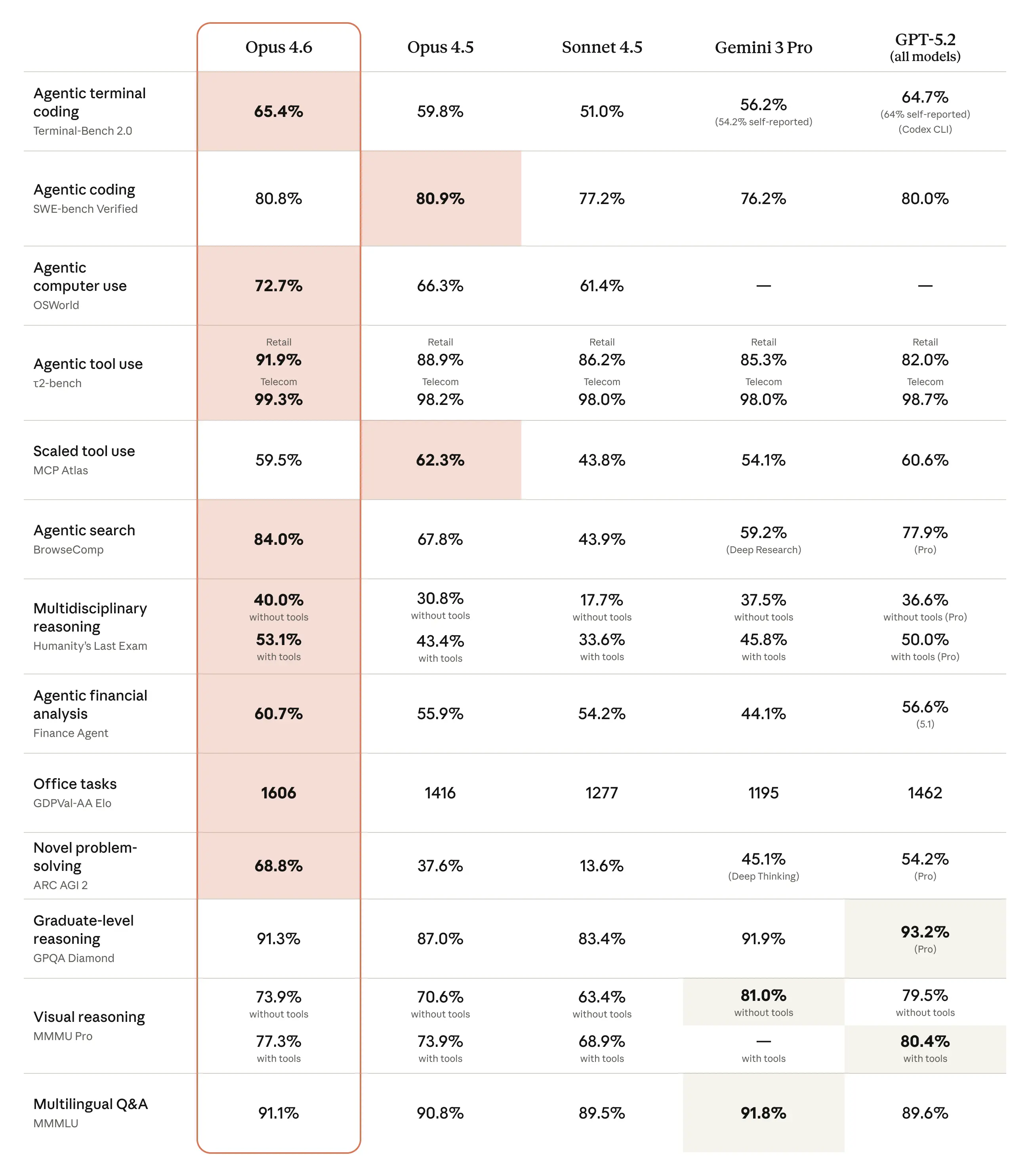 Tableau comparatif des benchmarks de Claude Opus 4.6, Source : Anthropic
Tableau comparatif des benchmarks de Claude Opus 4.6, Source : Anthropic
Codage agentique
Terminal-Bench 2.0 : N°1, Score le plus élevé de tous les modèles (évaluation de codage agentique)
SWE-bench Verified : 81,42 % (avec modification de prompt), en hausse par rapport aux 80,9 % d'Opus 4.5
MCP Atlas (effort max) : 62,7 %, leader de l'industrie
Opus 4.6 ne génère pas seulement du code, il planifie, exécute, débogue et itère sur des projets complexes multi-fichiers de manière plus fiable que tout concurrent.
Récupération en contexte long
MRCR v2 (8-aiguilles, variante 1M) :
- →Claude Opus 4.6 : 76 %
- →Claude Sonnet 4.5 : 18,5 %
C'est un changement qualitatif, pas une simple amélioration. À 76 %, Opus 4.6 peut de manière fiable trouver et utiliser des informations enfouies n'importe où dans un contexte d'un million de tokens. Les 18,5 % de Sonnet 4.5 signifient qu'il perd essentiellement la plupart des informations dans les contextes longs.
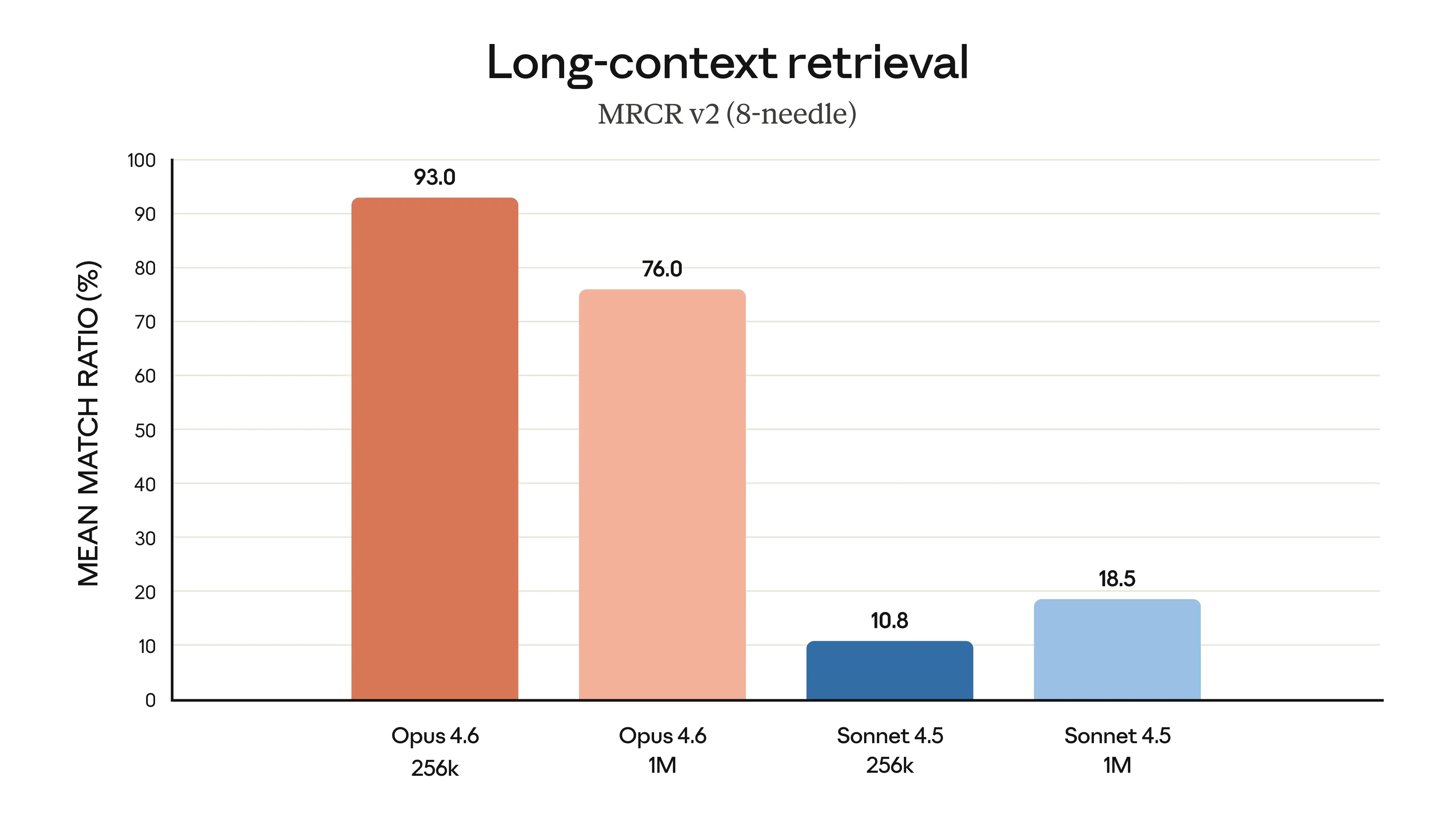 Opus 4.6 montre une amélioration significative de la récupération en contexte long, Source : Anthropic
Opus 4.6 montre une amélioration significative de la récupération en contexte long, Source : Anthropic
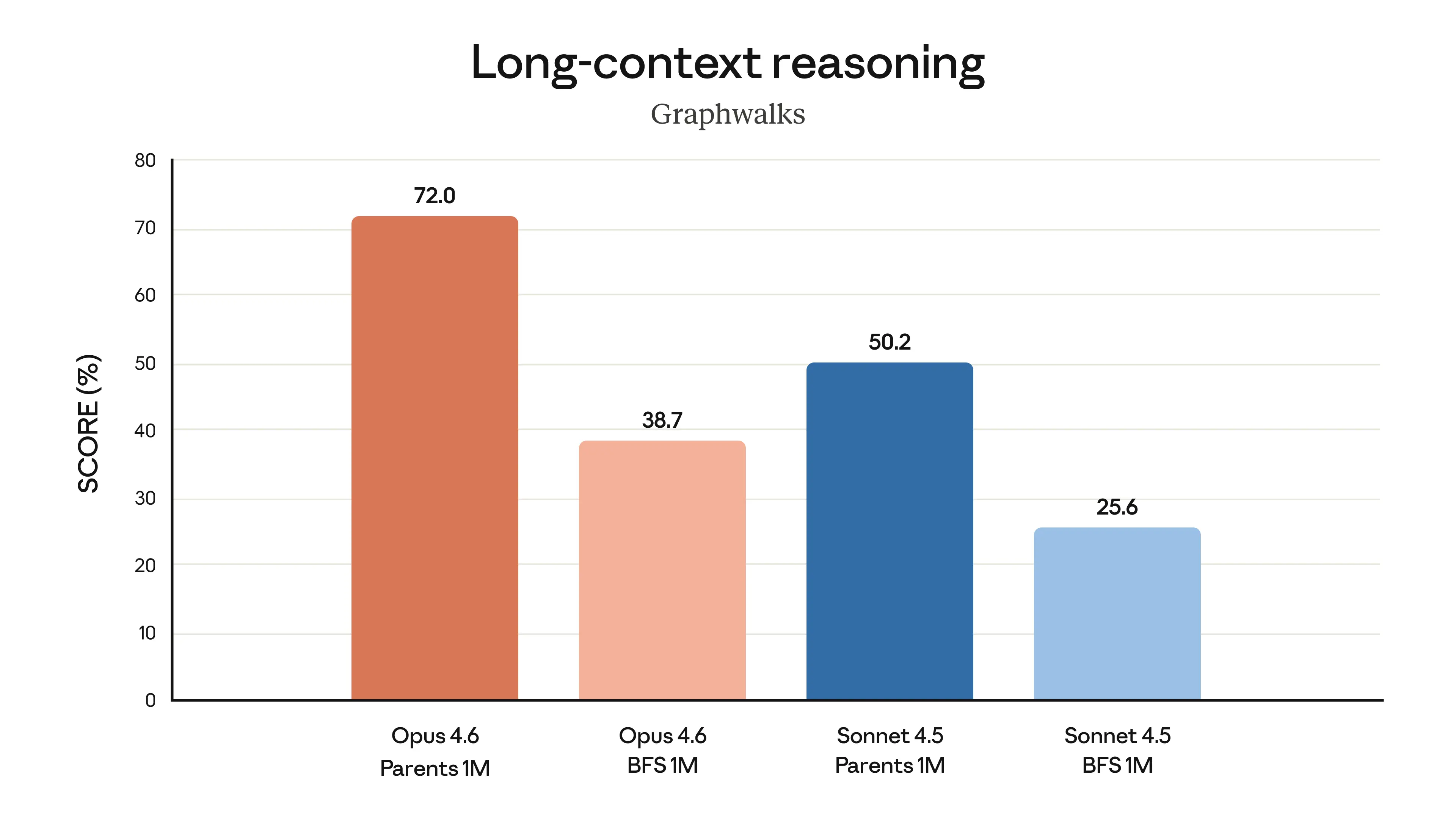 Opus 4.6 excelle au raisonnement approfondi sur des contextes longs, Source : Anthropic
Opus 4.6 excelle au raisonnement approfondi sur des contextes longs, Source : Anthropic
Raisonnement complexe
Humanity's Last Exam : En tête de tous les modèles de pointe, le benchmark de raisonnement multidisciplinaire le plus difficile disponible.
GDPval-AA (tâches de travail réel) : Surpasse GPT-5.2 d'environ 144 points Elo et Opus 4.5 de 190 points Elo.
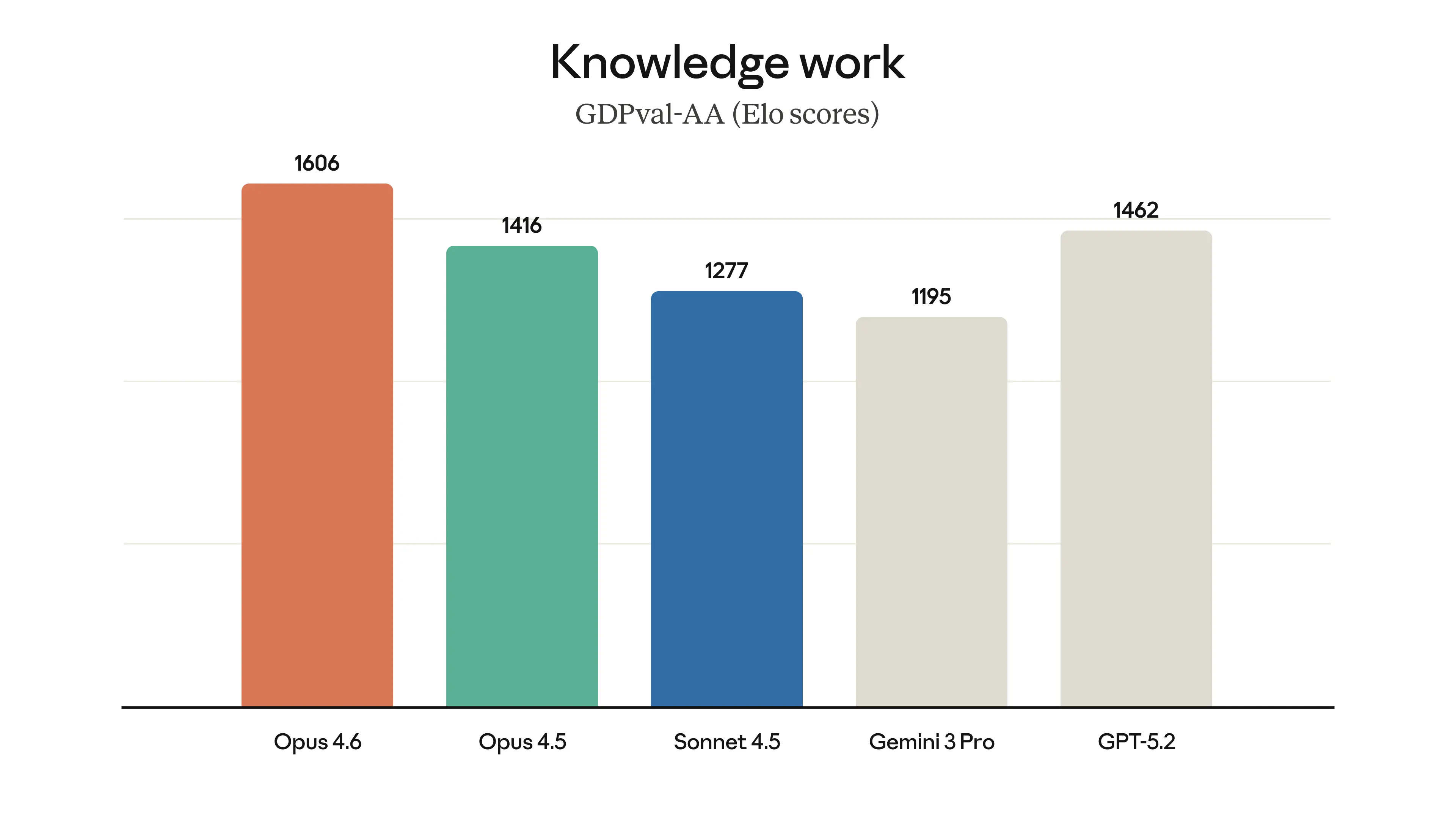 Opus 4.6 est à la pointe sur les tâches de travail réel dans plusieurs domaines professionnels, Source : Anthropic
Opus 4.6 est à la pointe sur les tâches de travail réel dans plusieurs domaines professionnels, Source : Anthropic
Récupération d'information
BrowseComp : Meilleur de tous les modèles pour trouver des informations difficiles à trouver en ligne.
- →Score avec harnais multi-agents : 86,8 %
Domaines spécialisés
Cybersécurité (évaluation NBIM) : A remporté 38 des 40 investigations de cybersécurité en classement aveugle contre les modèles Claude 4.5.
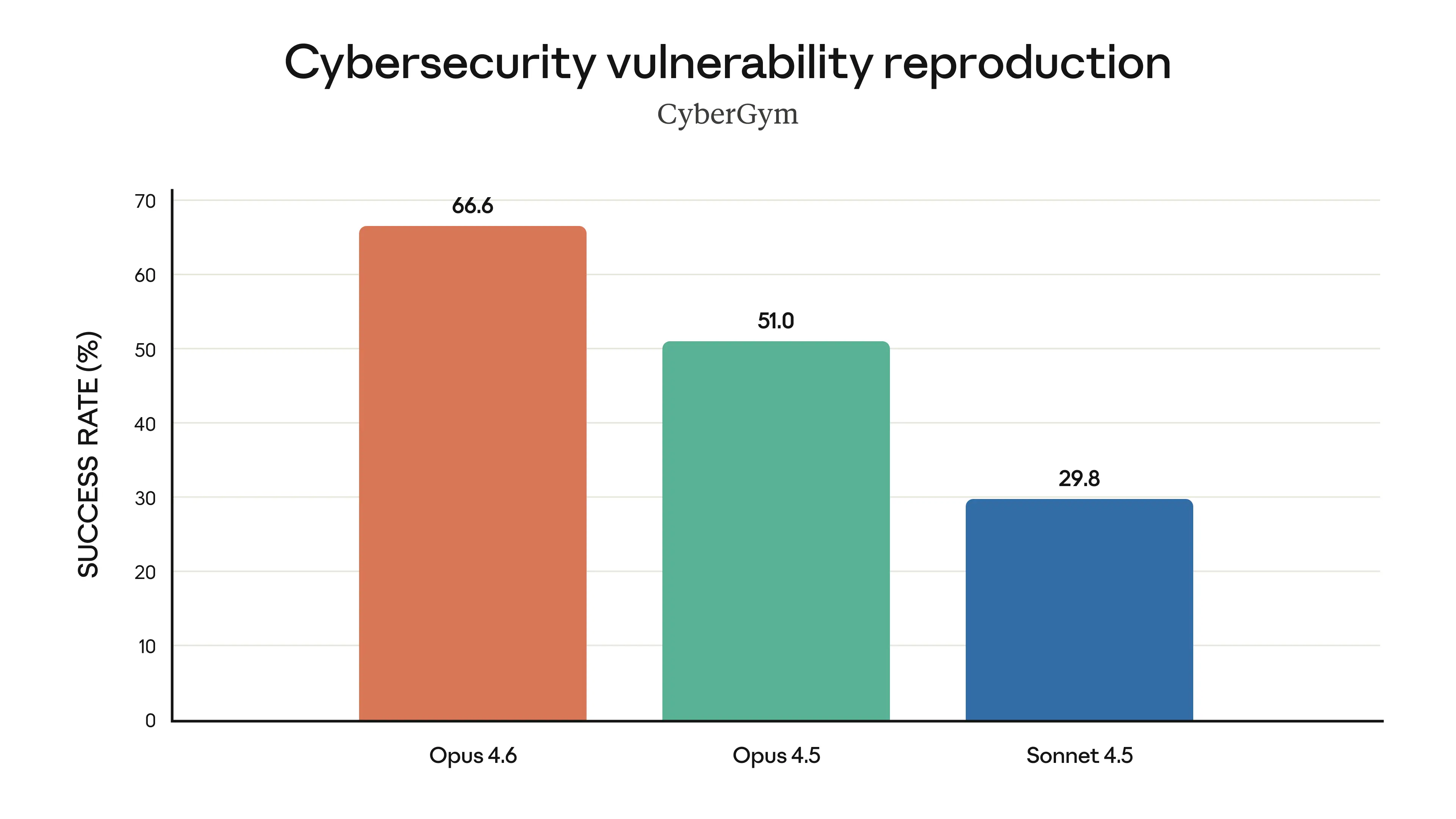 Opus 4.6 trouve des vulnérabilités réelles dans les bases de code mieux que tout autre modèle, Source : Anthropic
Opus 4.6 trouve des vulnérabilités réelles dans les bases de code mieux que tout autre modèle, Source : Anthropic
Juridique (BigLaw Bench par Harvey) : 90,2 % au total, avec 40 % de scores parfaits, exceptionnel pour l'analyse juridique.
Sciences de la vie : Presque 2× meilleur qu'Opus 4.5 en biologie computationnelle, biologie structurale, chimie organique et phylogénétique.
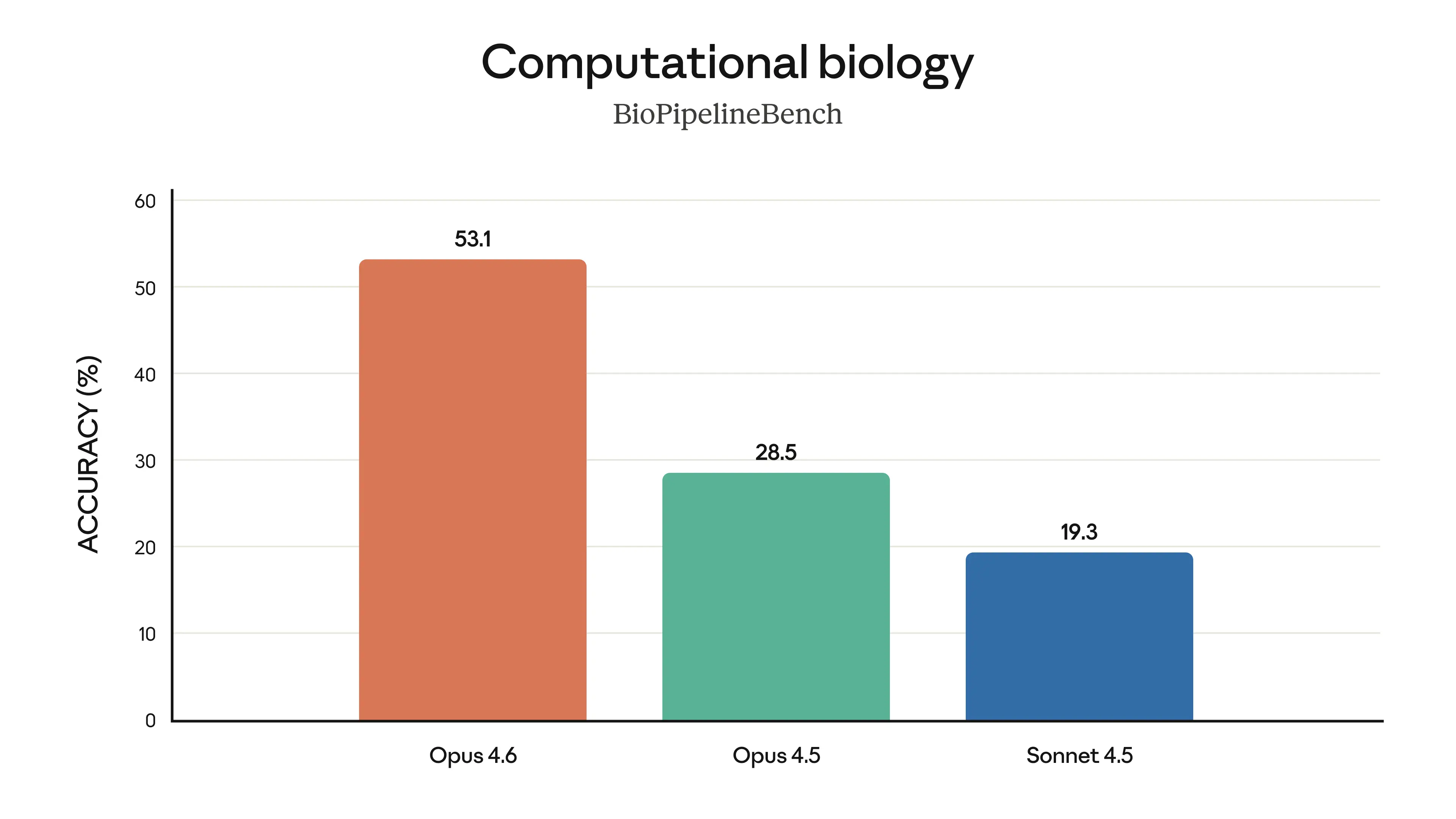 Opus 4.6 est presque 2× meilleur qu'Opus 4.5 en biologie computationnelle, biologie structurale, chimie organique et phylogénétique, Source : Anthropic
Opus 4.6 est presque 2× meilleur qu'Opus 4.5 en biologie computationnelle, biologie structurale, chimie organique et phylogénétique, Source : Anthropic
Analyse des causes racines (OpenRCA) : Excelle dans le diagnostic des pannes logicielles complexes.
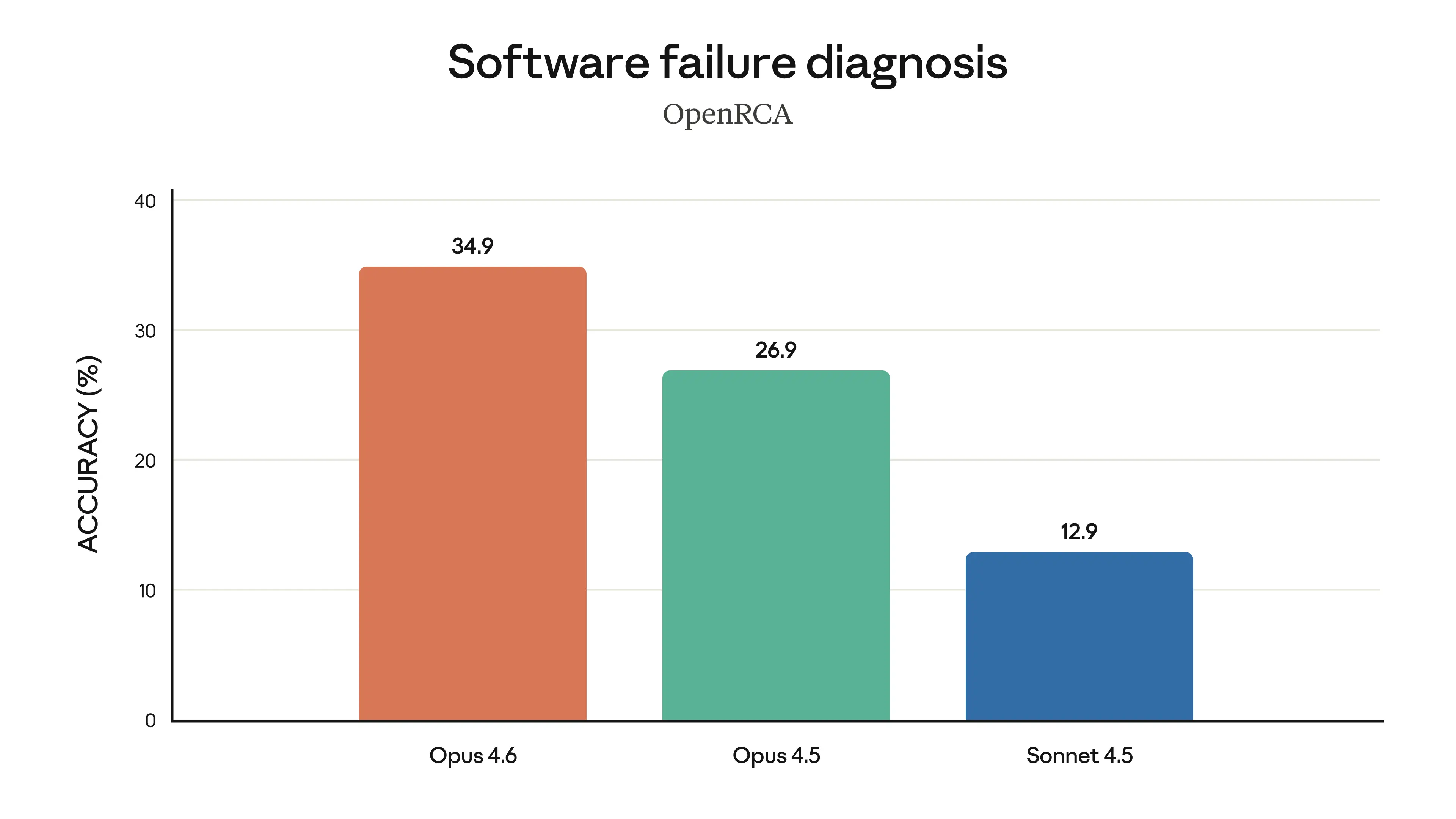 Opus 4.6 excelle dans le diagnostic des pannes logicielles complexes, Source : Anthropic
Opus 4.6 excelle dans le diagnostic des pannes logicielles complexes, Source : Anthropic
Codage multilingue (SWE-bench) : Résout des problèmes dans plusieurs langages de programmation.
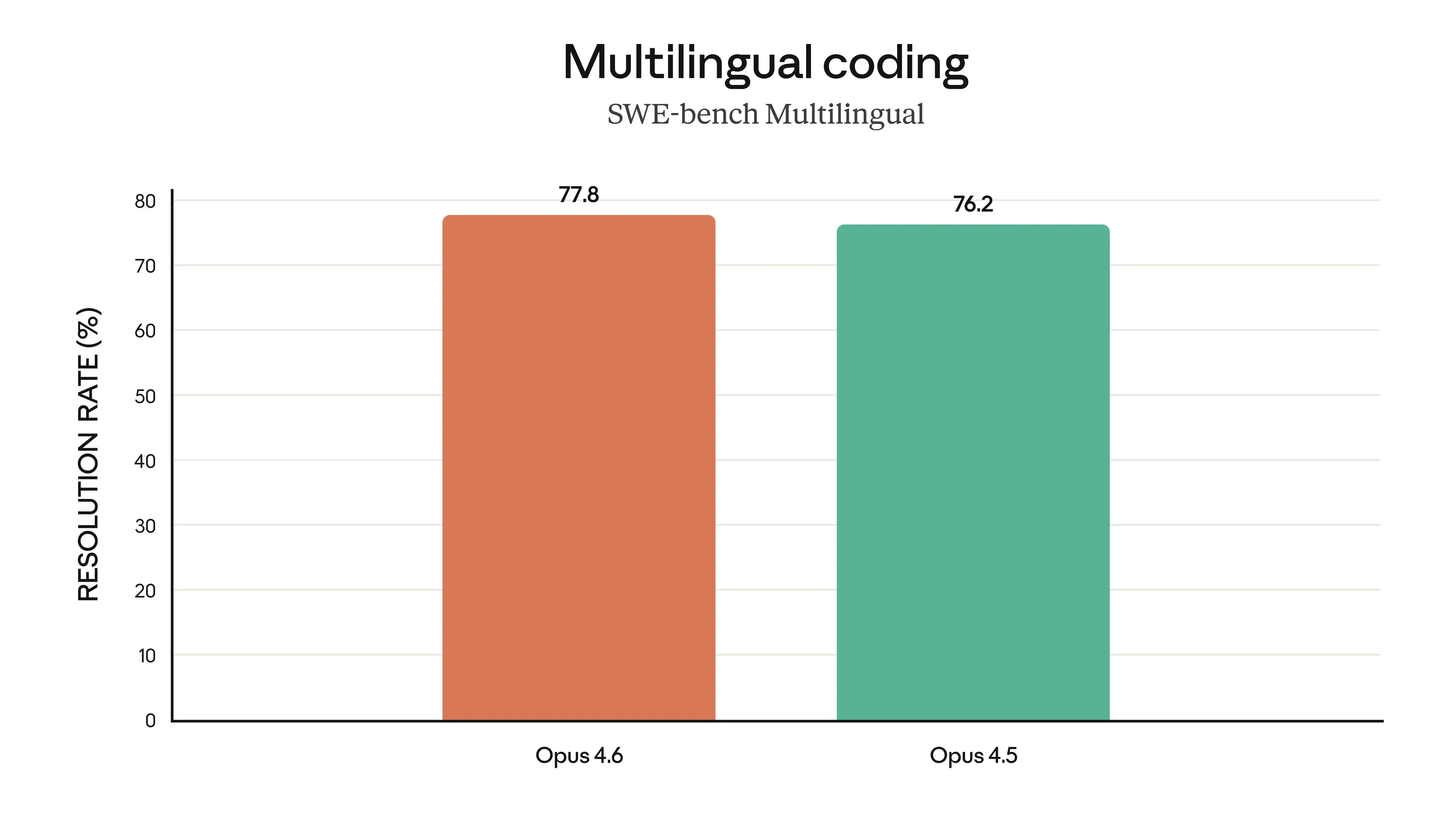 Opus 4.6 résout des problèmes d'ingénierie logicielle dans différents langages de programmation, Source : Anthropic
Opus 4.6 résout des problèmes d'ingénierie logicielle dans différents langages de programmation, Source : Anthropic
Cohérence à long terme (Vending-Bench 2) : Maintient la concentration dans le temps, gagnant 3 050,53 $ de plus qu'Opus 4.5.
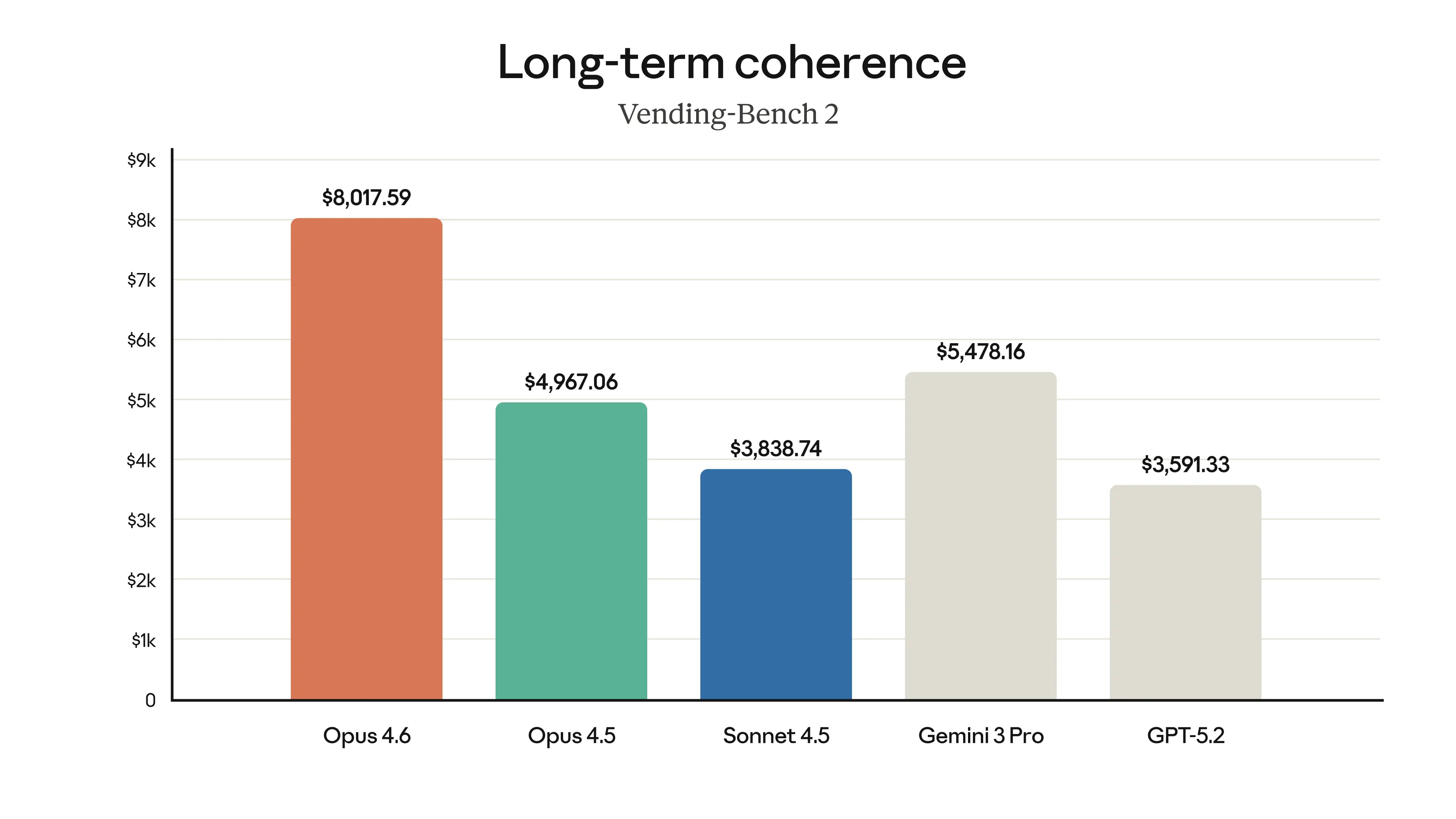 Opus 4.6 maintient la concentration dans le temps et gagne 3 050,53 $ de plus qu'Opus 4.5 sur Vending-Bench 2, Source : Anthropic
Opus 4.6 maintient la concentration dans le temps et gagne 3 050,53 $ de plus qu'Opus 4.5 sur Vending-Bench 2, Source : Anthropic
Fonctionnalités clés en détail
Codage agentique avec Claude Code
Opus 4.6 alimente la dernière version de Claude Code, l'agent de codage d'Anthropic. Améliorations clés :
Planification plus soignée : Avant d'apporter des modifications, Opus 4.6 crée des plans d'exécution détaillés, réduisant les erreurs sur les grandes tâches de refactoring.
Tâches longues soutenues : La compaction de contexte signifie que les sessions de codage peuvent durer des heures sans dégradation du contexte. Le modèle résume le travail antérieur pour libérer du contexte pour les opérations en cours.
Équipes d'agents (aperçu recherche) :
Utilisateur : « Ajoutez l'authentification à cette app Next.js
avec OAuth, sessions en base de données et contrôle d'accès
basé sur les rôles. »
Claude Code lance :
→ Agent 1 : Intégration des fournisseurs OAuth (Google, GitHub)
→ Agent 2 : Schéma de base de données + gestion des sessions
→ Agent 3 : Middleware + protection des routes basée sur les rôles
→ Coordinateur : Fusionne le travail, résout les conflits, lance les tests
Support de bases de code plus grandes : Avec un contexte de 1M, Opus 4.6 peut comprendre des bases de code entières de taille moyenne à grande en une seule session, maintenant la conscience des patterns architecturaux, des conventions de nommage et des dépendances inter-fichiers.
Travail intellectuel et traitement de documents
📺 Claude Opus 4.6 en action
Source : YouTube Anthropic, Démo des capacités de Claude Opus 4.6, 5 février 2026.
Opus 4.6 excelle dans les tâches nécessitant la synthèse de grands volumes d'information :
- →Analyse financière : Traiter les rapports trimestriels, identifier les tendances, générer des résumés avec des points de données spécifiques
- →Synthèse de recherche : Analyser des centaines d'articles, extraire les méthodologies, comparer les résultats
- →Revue juridique : Analyser des ensembles de contrats, identifier les incohérences, signaler les clauses à risque (90,2 % sur BigLaw Bench)
- →Création de documents : Générer des rapports, tableurs et présentations via Claude Cowork
Intégration avec Claude Cowork
Claude Cowork fonctionne désormais sur Opus 4.6 comme modèle de base (claude-sonnet-4-5-20250929 était utilisé précédemment). Cela signifie :
- →Meilleur traitement des fichiers : Extraction plus précise des PDF, tableurs et documents
- →Organisation plus intelligente : Meilleure compréhension des relations entre fichiers et du contenu
- →Sessions plus longues : La compaction de contexte permet des tâches d'automatisation de plusieurs heures
- →Précision améliorée : Moins d'erreurs sur les flux de travail complexes multi-étapes
Claude dans Excel et Claude dans PowerPoint (nouveau)
Anthropic a apporté des améliorations substantielles à Claude dans Excel et lance Claude dans PowerPoint en aperçu recherche :
- →Claude dans Excel : Gère les tâches plus difficiles et de longue durée, peut planifier avant d'agir, ingérer des données non structurées et déduire la bonne structure, et gérer des changements multi-étapes en une seule passe
- →Claude dans PowerPoint : Lit vos mises en page, polices et masques de diapositives pour rester fidèle à votre charte graphique, génère des présentations complètes à partir de descriptions ou de modèles. Disponible pour les plans Max, Team et Enterprise
Cette intégration fait de Claude un véritable outil de productivité pour le travail bureautique quotidien, pas seulement un assistant de codage.
Tarifs et disponibilité
Tarifs API
| Niveau | Entrée | Sortie |
|---|---|---|
| Standard (≤200K contexte) | 5 $ / M tokens | 25 $ / M tokens |
| Bêta contexte 1M (>200K) | 10 $ / M tokens | 37,50 $ / M tokens |
| Inférence US uniquement | 1,1× standard | 1,1× standard |
Accès par abonnement
| Formule | Prix | Accès Opus 4.6 |
|---|---|---|
| Gratuit | 0 $/mois | ❌ Pas d'accès |
| Pro | 17-20 $/mois | ✅ Usage limité |
| Max | 100-200 $/mois | ✅ Limites supérieures |
| Enterprise | Sur mesure | ✅ Accès complet |
Disponibilité par plateforme
Opus 4.6 est disponible sur toutes les principales plateformes dès le premier jour :
- →claude.ai, Accès web direct
- →API Anthropic, Identifiant modèle :
claude-opus-4-6 - →AWS Bedrock,
anthropic.claude-opus-4-6-v1 - →Google Vertex AI,
claude-opus-4-6 - →Claude Code, Agent de codage desktop
- →Claude Cowork, Agent d'automatisation desktop
Comment utiliser Opus 4.6
Démarrage rapide API
import anthropic
client = anthropic.Anthropic()
# Utilisation standard avec pensée adaptative (par défaut)
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
messages=[
{"role": "user", "content": "Analyze this codebase and suggest architectural improvements."}
]
)
# Avec effort maximum explicite pour les tâches complexes
response = client.messages.create(
model="claude-opus-4-6",
max_tokens=16384,
thinking={
"type": "enabled",
"budget_tokens": 120000 # Effort maximum
},
messages=[
{"role": "user", "content": "Solve this complex mathematical proof..."}
]
)
Bonnes pratiques
- →
Laissez la pensée adaptative fonctionner : Ne définissez pas de niveaux d'effort manuels sauf si vous avez une raison spécifique. Le système adaptatif du modèle est très efficace pour choisir la bonne profondeur de raisonnement.
- →
Exploitez le contexte de 1M : Pour les grandes bases de code ou ensembles de documents, fournissez tout dans le contexte plutôt que de résumer manuellement. Le score MRCR v2 de 76 % d'Opus 4.6 signifie qu'il retient véritablement l'information sur toute la fenêtre.
- →
Utilisez les équipes d'agents pour le travail parallèle : Quand votre tâche a des sous-tâches indépendantes, activez les équipes d'agents dans Claude Code pour paralléliser le travail.
- →
Activez la compaction de contexte pour les longues sessions : Pour les tâches durant plus d'une heure, activez la compaction de contexte pour éviter la dégradation.
- →
Comparez avec Sonnet pour optimiser les coûts : Toute tâche ne nécessite pas Opus. Utilisez Sonnet 4.5 pour les tâches routinières et réservez Opus 4.6 pour le raisonnement complexe, le travail en contexte long et le codage agentique.
Cas d'usage et recommandations
Quand utiliser Opus 4.6
| Cas d'usage | Pourquoi Opus 4.6 | Alternative |
|---|---|---|
| Refactoring de grandes bases de code | Contexte 1M + équipes d'agents | Claude Code avec Sonnet (projets plus petits) |
| Revue de documents juridiques | 90,2 % BigLaw Bench, contexte long | Revue manuelle (pour vérification finale) |
| Synthèse de recherche (100+ articles) | Contexte 1M, forte récupération | Gemini (si >1M tokens nécessaires) |
| Investigation cybersécurité | 38/40 victoires aveugles vs modèles 4.5 | GPT-5.3-Codex (pour tests d'exploitation actifs) |
| Analyse financière | Raisonnement approfondi + traitement de documents | GPT-5.2 (pour graphiques visuels) |
| Automatisation complexe multi-étapes | Cowork + compaction de contexte | Outils d'automatisation plus simples (pour étape unique) |
Quand NE PAS utiliser Opus 4.6
- →Questions-réponses simples ou chat : Utilisez Sonnet 4.5 ou Haiku, plus rapide et moins cher
- →Auto-complétion en temps réel : Utilisez des modèles de codage spécialisés dans l'IDE
- →Génération d'images : Claude ne génère pas d'images
- →Tâches de moins de 1K tokens : Surdimensionné, utilisez des modèles plus petits
Sécurité et alignement
Anthropic rapporte qu'Opus 4.6 a le taux de refus excessif le plus bas de tous les modèles Claude récents, ce qui signifie qu'il est moins susceptible de refuser inutilement des requêtes raisonnables tout en maintenant de solides frontières de sécurité.
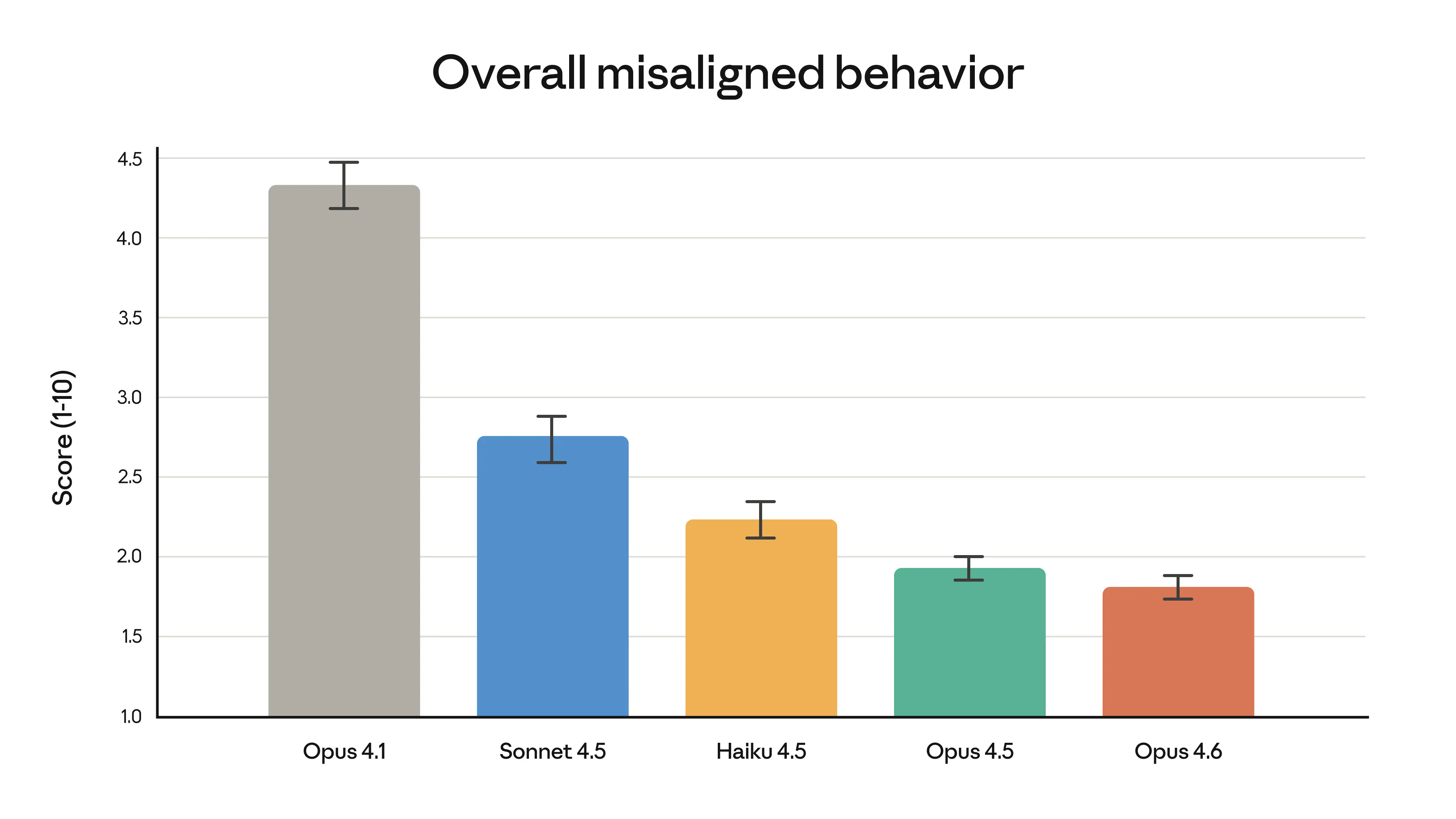 Le score global de comportement désaligné pour chaque modèle Claude récent dans l'audit comportemental automatisé d'Anthropic, Source : Anthropic
Le score global de comportement désaligné pour chaque modèle Claude récent dans l'audit comportemental automatisé d'Anthropic, Source : Anthropic
Propriétés de sécurité clés
- →Faible taux de tromperie : Instances minimales de comportements désalignés incluant la flagornerie et les illusions
- →Alignement robuste : Profil de sécurité égal ou supérieur à celui de tout modèle de pointe
- →Évaluation complète : 6 nouvelles sondes de cybersécurité ont été développées spécifiquement pour cette version
- →System card publiée : Transparence totale sur les capacités et limitations
Sécurité vs modèles précédents
Opus 4.6 atteint un équilibre difficile : il est plus performant et moins restrictif simultanément. Le taux de refus excessif plus bas signifie moins de faux positifs (requêtes légitimes refusées), tandis que l'évaluation de sécurité améliorée signifie que les requêtes véritablement nuisibles sont toujours détectées.
Retours des partenaires en accès anticipé
De grandes entreprises ont validé les capacités d'Opus 4.6 avec des témoignages directs :
« Claude Opus 4.6 est la nouvelle frontière sur les tâches de longue durée selon nos benchmarks internes et nos tests. Il s'est également révélé très efficace pour la revue de code. » , Michael Truell, Co-fondateur et CEO, Cursor
« Claude Opus 4.6 a atteint le score BigLaw Bench le plus élevé de tous les modèles Claude à 90,2 %. Avec 40 % de scores parfaits et 84 % au-dessus de 0,8, il est remarquablement performant pour le raisonnement juridique. » , Niko Grupen, Responsable Recherche IA, Harvey
« Claude Opus 4.6 a fermé de manière autonome 13 issues et assigné 12 issues aux bons membres de l'équipe en une seule journée, gérant une organisation d'environ 50 personnes sur 6 dépôts. » , Yusuke Kaji, Directeur Général IA, Rakuten
« Claude Opus 4.6 apporte une amélioration de la qualité du design. Il fonctionne parfaitement avec nos systèmes de design et il est plus autonome, ce qui est au cœur des valeurs de Lovable. » , Fabian Hedin, Co-fondateur, Lovable
Toutes les citations proviennent de l'annonce officielle d'Anthropic.
Partenaires supplémentaires : GitHub, Windsurf, NBIM, Notion, Asana, Figma, Shopify, Vercel, Thomson Reuters, Ramp, Box, Cognition (Devin) et Bolt.new.
FAQ
Quelle est la différence entre Claude Opus 4.6 et Sonnet 4.5 ?
Opus 4.6 est le modèle le plus performant d'Anthropic, conçu pour les tâches complexes nécessitant un raisonnement approfondi, une compréhension en contexte long et un codage agentique. Sonnet 4.5 est plus rapide et moins cher, mieux adapté aux tâches routinières. Différences clés : Opus a un contexte de 1M (vs 200K), la pensée adaptative et des scores de benchmark significativement plus élevés.
Claude Opus 4.6 vaut-il la mise à niveau depuis 4.5 ?
Oui, pour la plupart des cas d'usage professionnels. La réduction de prix de 67 % seule le rend convaincant, vous obtenez un modèle plus performant pour moins cher. La fenêtre de contexte de 1M, la pensée adaptative et le codage agentique amélioré en font une mise à niveau substantielle, pas une amélioration incrémentale.
Comment fonctionne la compaction de contexte ?
Lorsqu'elle est activée, Opus 4.6 résume automatiquement les parties anciennes du contexte de conversation pour libérer de l'espace pour de nouvelles informations. Cela permet aux sessions agentiques de durer des heures sans atteindre les limites de contexte ni perdre le fil de la tâche globale.
Puis-je utiliser Opus 4.6 dans Cursor ou d'autres IDE ?
Opus 4.6 est disponible via l'API Anthropic, ce qui signifie que tout IDE ou outil supportant des points d'accès API personnalisés peut l'utiliser. Claude Code (l'agent de codage natif d'Anthropic) exécute Opus 4.6 nativement avec le support complet des équipes d'agents.
Quels langages Opus 4.6 supporte-t-il pour le codage ?
Opus 4.6 supporte tous les principaux langages de programmation incluant Python, JavaScript/TypeScript, Java, C/C++, Rust, Go, Ruby, PHP, Swift, Kotlin et plus encore. Il excelle particulièrement en Python et TypeScript selon les performances benchmark.
- →Claude Opus 4.6 vs GPT-5.3 Codex, Comparaison face à face
- →Guide GPT-5.3 Codex, Le nouveau modèle de codage d'OpenAI
- →Guide Claude Cowork, L'agent desktop d'Anthropic
- →Benchmarks LLM 2026, Comparaison complète des modèles
- →Comparaison des éditeurs de code IA, Benchmarks des IDE
Ce qu'il faut retenir
- →
Claude Opus 4.6 est le modèle le plus puissant d'Anthropic, sorti le 5 février 2026 avec un codage agentique et des capacités de contexte long de pointe
- →
Fenêtre de contexte de 1M de tokens (bêta) permettant de travailler avec des bases de code entières et des ensembles massifs de documents, avec 76 % MRCR v2 prouvant une rétention d'information réelle
- →
La pensée adaptative élimine le besoin de définir manuellement l'effort de raisonnement, le modèle décide quand réfléchir plus en profondeur
- →
Réduction de prix de 67 % par rapport à Opus 4.5, rendant les capacités de pointe significativement plus accessibles
- →
Les équipes d'agents et la compaction de contexte permettent des sessions de codage parallélisées de plusieurs heures dans Claude Code
- →
Benchmarks leaders : Terminal-Bench 2.0 N°1, Humanity's Last Exam N°1, BrowseComp 86,8 %, BigLaw Bench 90,2 %
- →
Disponible partout : API, claude.ai, AWS Bedrock, Google Vertex AI, avec une intégration complète à l'écosystème
Tirer le Meilleur Parti de Claude Opus 4.6
Voici les conseils pratiques issus du tutoriel officiel Anthropic pour maximiser les performances d'Opus 4.6 :
Exploitez le Thinking Adaptatif
Opus 4.6 ajuste automatiquement son effort de raisonnement selon la complexité. Pour en tirer parti :
- →Questions simples : Opus répond rapidement sans thinking étendu, pas besoin de configuration
- →Problèmes complexes : Augmentez le
budget_tokenspour permettre une réflexion plus approfondie - →Codage multi-fichier : Activez l'extended thinking pour les refactorisations complexes
# Exemple : Forcer un raisonnement approfondi
response = client.messages.create(
model="claude-opus-4-6-20260610",
max_tokens=16000,
thinking={
"type": "enabled",
"budget_tokens": 10000 # Budget généreux pour les tâches complexes
},
messages=[{"role": "user", "content": "Analyse cette architecture microservices..."}]
)
Conseils par Cas d'Usage
| Cas d'usage | Conseil | Paramètre recommandé |
|---|---|---|
| Analyse de code | Fournir le contexte complet du fichier | budget_tokens: 8000+ |
| Rédaction créative | Laisser le thinking adaptatif décider | Default (pas de budget fixe) |
| Mathématiques/Logique | Maximiser le budget thinking | budget_tokens: 12000+ |
| Résumé rapide | Désactiver l'extended thinking | thinking: disabled |
| Débogage | Inclure les logs d'erreur complets | budget_tokens: 6000+ |
Bonnes Pratiques Opus 4.6
- →Soyez spécifique dans vos instructions, Opus excelle quand les attentes sont claires
- →Utilisez les system prompts, Définissez le rôle et les contraintes dès le départ
- →Itérez avec des conversations multi-tours, Opus maintient un excellent contexte
- →Combinez avec les outils, Tool use + thinking = résultats supérieurs
- →Surveillez les coûts, Le thinking étendu consomme des tokens supplémentaires
Astuce Pro : Pour les tâches de codage, combinez Opus 4.6 avec Claude Code pour bénéficier du thinking adaptatif directement dans votre IDE.
📚 Allez plus loin : Consultez notre guide complet de l'extended thinking pour maîtriser cette fonctionnalité.
Maîtrisez les flux de travail avancés de prompts avec l'IA
La pensée adaptative et les équipes d'agents de Claude Opus 4.6 représentent la pointe des flux de travail assistés par l'IA. Comprendre comment structurer des tâches complexes, chaîner des prompts et orchestrer des systèmes multi-agents vous aidera à tirer le meilleur parti de ce modèle.
Dans notre Module 4, Chaînage et routage, vous apprendrez :
- →Comment concevoir des flux de travail de prompts multi-étapes
- →Le routage conditionnel basé sur la complexité de l'entrée
- →La construction de points de vérification pour les sorties générées par l'IA
- →Quand utiliser une approche à modèle unique vs multi-agents
- →L'optimisation des coûts entre les niveaux de modèles
→ Découvrir le Module 4 : Chaînage et routage
Dernière mise à jour : 6 février 2026 Fonctionnalités et spécifications vérifiées à partir de l'annonce officielle d'Anthropic et de la documentation API.
Module 4 — Chaining & Routing
Build multi-step prompt workflows with conditional logic.
Dorian Laurenceau
Full-Stack Developer & Learning DesignerFull-stack web developer and learning designer. I spent 4 years as a freelance full-stack developer and 4 years teaching React, JavaScript, HTML/CSS and WordPress to adult learners. Today I design learning paths in web development and AI, grounded in learning science. I founded learn-prompting.fr to make AI practical and accessible, and built the Bluff app to gamify political transparency.
Weekly AI Insights
Tools, techniques & news — curated for AI practitioners. Free, no spam.
Free, no spam. Unsubscribe anytime.
→Related Articles
FAQ
Qu'est-ce que Claude Opus 4.6 ?+
Claude Opus 4.6 est le modèle IA le plus performant d'Anthropic, sorti le 5 février 2026. Il dispose d'une fenêtre de contexte de 1M de tokens (bêta), d'une pensée adaptative, d'une sortie maximale de 128K et de performances de pointe sur les benchmarks de codage agentique, de récupération en contexte long et de cybersécurité.
Combien coûte Claude Opus 4.6 ?+
Via API : 5 $ par million de tokens en entrée, 25 $ par million de tokens en sortie. Pour les prompts de plus de 200K tokens (bêta 1M) : 10 $/37,50 $. Via les abonnements Claude Pro (17-20 $/mois) ou Claude Max (100-200 $/mois).
Qu'est-ce que la pensée adaptative dans Claude Opus 4.6 ?+
La pensée adaptative est une nouvelle fonctionnalité où Opus 4.6 décide de manière autonome quand un raisonnement plus approfondi est utile, plutôt que de demander à l'utilisateur de spécifier l'effort de réflexion. Le modèle ajuste sa profondeur de raisonnement en fonction de la complexité de la tâche.
Comment Opus 4.6 se compare-t-il à Opus 4.5 ?+
Opus 4.6 offre une fenêtre de contexte de 1M (vs 200K), une pensée adaptative, un prix d'entrée 67 % inférieur (5 $ vs 15 $), un score MRCR v2 en contexte long de 76 % (vs 18,5 % pour Sonnet 4.5), et un codage agentique amélioré avec des équipes d'agents et la compaction de contexte.
Claude Opus 4.6 supporte-t-il le contexte de 1 million de tokens ?+
Oui. Opus 4.6 est le premier modèle de classe Opus à supporter une fenêtre de contexte de 1M de tokens en bêta. Le contexte standard reste à 200K tokens, avec l'option 1M disponible pour les prompts dépassant 200K tokens à un tarif légèrement supérieur.
Sur quels benchmarks Claude Opus 4.6 est-il leader ?+
Opus 4.6 est en tête sur Terminal-Bench 2.0 (codage agentique), Humanity's Last Exam (raisonnement complexe), BrowseComp avec 86,8 % (récupération d'information), et GDPval-AA (travail réel), surpassant GPT-5.2 d'environ 144 points Elo.
Claude Opus 4.6 peut-il être utilisé pour le codage ?+
Oui. Opus 4.6 est à la pointe pour le codage agentique, en tête de Terminal-Bench 2.0 et atteignant 81,42 % sur SWE-bench Verified. Il alimente Claude Code avec de nouvelles fonctionnalités comme les équipes d'agents (agents de codage parallèles) et la compaction de contexte.
Claude Opus 4.6 est-il disponible sur AWS et Google Cloud ?+
Oui. Opus 4.6 est disponible sur claude.ai, l'API Anthropic (identifiant modèle : claude-opus-4-6), AWS Bedrock (anthropic.claude-opus-4-6-v1) et Google Vertex AI (claude-opus-4-6).