GPT-5.3 Codex : guide complet, benchmarks et comment
By Dorian Laurenceau
GPT-5.3 Codex : le modèle de codage agentique le plus puissant d'OpenAI (2026)
📅 Dernière révision : 24 avril 2026. Mise à jour avec les retours et observations d'avril 2026.
📚 Articles liés : GPT-5.2 Codex en détail | Claude Opus 4.6 vs GPT-5.3 Codex | Comparaison des éditeurs de code IA | Guide de prompting ChatGPT 5.2
- →GPT-5.3 vs GPT-5.3-Codex : clarification
- →Performances aux benchmarks
- →Capacités clés
- →Self-bootstrapping : une étape majeure
- →Cybersécurité : première classification « High »
- →Disponibilité et accès
- →Cas d'usage pratiques
- →Limitations
- →FAQ
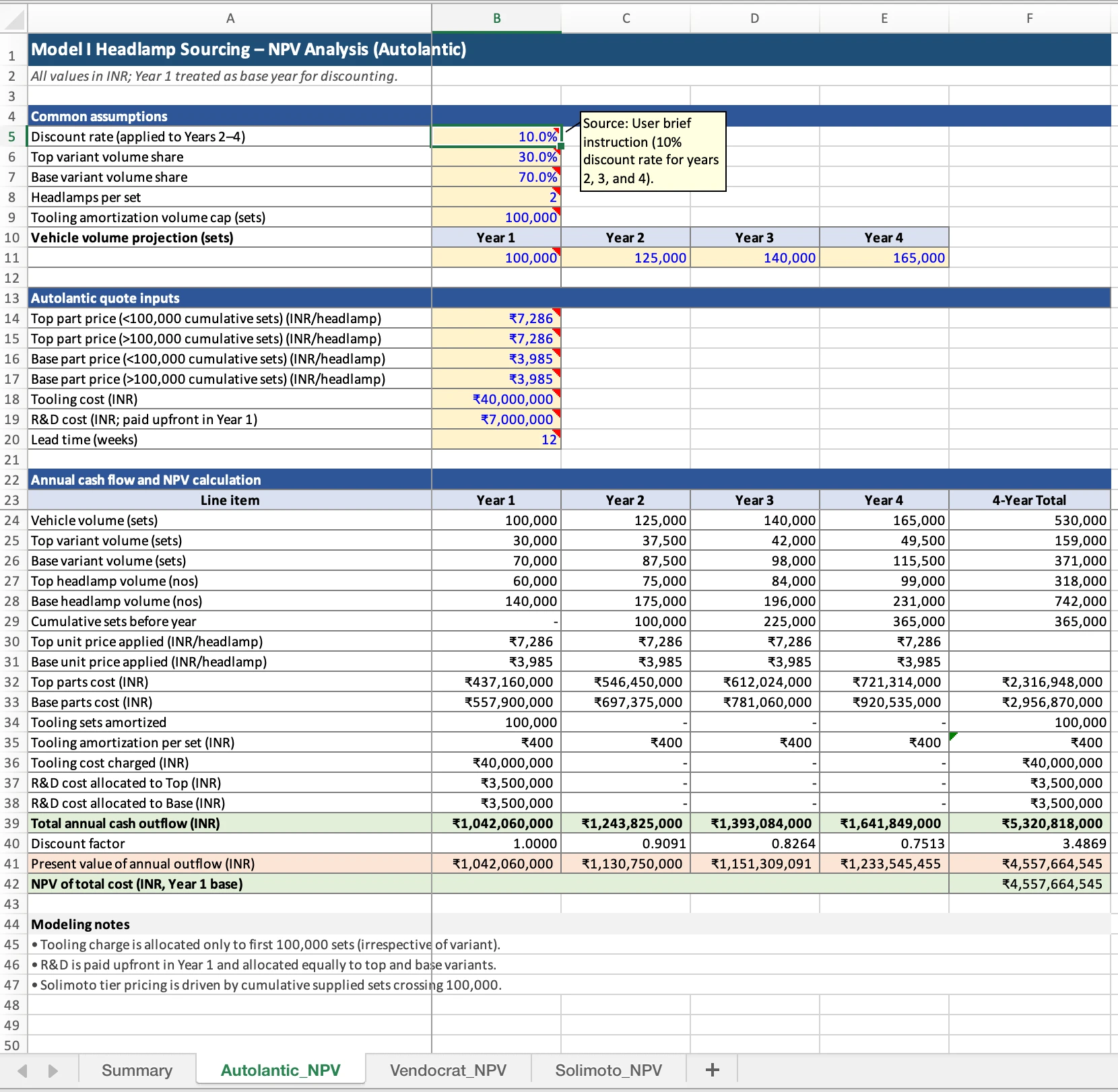
Le 5 février 2026, OpenAI a lancé GPT-5.3-Codex, son modèle de codage agentique le plus puissant. Il ne s'agit pas d'une mise à jour incrémentale : GPT-5.3-Codex est le premier modèle d'IA classé « High » en cybersécurité selon le Preparedness Framework d'OpenAI, le premier modèle directement entraîné pour identifier les vulnérabilités logicielles, et le premier modèle ayant contribué à sa propre création grâce au self-bootstrapping.
Clarification importante : il n'existe pas de modèle généraliste « GPT-5.3 » distinct. Ce que les gens appellent « GPT 5.3 » est spécifiquement GPT-5.3-Codex, un modèle spécialisé optimisé pour le codage, le débogage et la cybersécurité. Le modèle généraliste actuel d'OpenAI reste GPT-5.2.
Avec un score de 77,3 % sur Terminal-Bench 2.0 (contre 64,0 % pour son prédécesseur), 64,7 % sur OSWorld-Verified (contre 38,2 %), et une classification cybersécurité inédite, GPT-5.3-Codex représente un changement d'échelle dans les capacités des agents de codage IA. Dans ce guide, nous couvrons tout : benchmarks, capacités, implications de sécurité et comment y accéder.
<!-- manual-insight -->
La classification cybersécurité « High » : ce que ça signifie vraiment, et pourquoi Reddit est divisé
La classification « High » en cybersécurité de GPT-5.3-Codex sous le Preparedness Framework d'OpenAI est la note sur laquelle la plupart des gens ont un avis sans avoir lu le framework. Les threads r/cybersecurity et r/LocalLLaMA du jour de lancement se séparent nettement en deux camps, et les deux ont un point.
Là où l'enthousiasme est justifié :
- →Découverte de vulnérabilités à l'échelle. Codex 5.3 qui trouve de vrais CVE dans des projets open-source pendant les tests pré-release n'est pas du spin marketing ; le post de lancement OpenAI documente des findings spécifiques divulgués de façon responsable. Pour les équipes sécurité, c'est une augmentation réelle.
- →Le self-bootstrapping est significatif, pas du hype. Qu'un modèle ait contribué de façon signifiante à l'entraînement de son successeur, c'est un shift qualitatif qui mérite d'être suivi. C'est aussi exactement la classe de capacité que le Preparedness Framework a été conçu pour signaler.
Là où le scepticisme est mérité :
- →« High » ne veut pas dire « opérateur cyber offensif autonome ». Le framework adresse explicitement l'uplift du modèle vers des attaquants humains, pas l'exploitation autonome bout-en-bout. Les threads Reddit qui cadrent ça en « l'IA peut maintenant tout hacker » lisent mal la note. La capacité est réelle ; le threat model est plus étroit que ne le suggèrent les hot takes.
- →Les cas d'usage défensifs ont la même surface de risque. Un modèle qui trouve des vulnérabilités peut être promptté pour les trouver dans votre code. C'est bien. Il peut aussi être promptté par quelqu'un d'autre pour les trouver dans vos services déployés. Le rate-limiting, le contrôle d'accès et la culture de disclosure responsable comptent plus que le nom du modèle.
Le cadrage mûr : traitez GPT-5.3-Codex comme un assistant de codage exceptionnellement capable et security-aware. La note vous dit de porter plus d'attention à la façon dont il est déployé, pas de paniquer sur des sauts de capacité. Associez-le à du code review, des audit logs et des credentials scopés, les mêmes contrôles que vous auriez dû avoir hier.
Learn AI — From Prompts to Agents
Qu'est-ce que GPT-5.3-Codex ?
GPT-5.3-Codex est le modèle de codage agentique conçu par OpenAI, successeur de GPT-5.2-Codex sorti le 18 décembre 2025. Il est conçu pour planifier, écrire, déboguer et déployer du code de manière autonome sur des projets multi-fichiers complexes avec une intervention humaine minimale.
Définition clé : GPT-5.3-Codex est un modèle d'IA agentique spécialisé sorti le 5 février 2026, optimisé pour le développement logiciel autonome, l'analyse de cybersécurité et l'utilisation d'ordinateur, fonctionnant 25 % plus vite que son prédécesseur tout en consommant moins de tokens par tâche.
Spécifications techniques
| Spécification | GPT-5.3-Codex | GPT-5.2-Codex (précédent) |
|---|---|---|
| Date de sortie | 5 février 2026 | 18 décembre 2025 |
| Type | Agent de codage spécialisé | Agent de codage spécialisé |
| Matériel d'entraînement | NVIDIA GB200 NVL72 | Non divulgué |
| Vitesse | 25 % plus rapide que le précédent | Référence |
| Efficacité en tokens | Moins de tokens que tout modèle antérieur | Référence |
| Classification cybersécurité | High (première fois) | Medium |
| Classification biologie | High | High |
| Auto-amélioration | N'atteint PAS le niveau High | N/A |
| Accès API | ❌ Pas encore disponible | ✅ Disponible |
| Accès ChatGPT | ✅ Forfaits payants | ✅ Forfaits payants |
GPT-5.3 vs GPT-5.3-Codex : clarification
Si vous avez cherché « GPT 5.3 » en espérant un nouveau modèle généraliste, voici ce qu'il faut savoir :
Chronologie de la famille de modèles GPT-5.x :
| Modèle | Date de sortie | Type |
|---|---|---|
| GPT-5 | 7 août 2025 | Généraliste |
| GPT-5.1 | 12 novembre 2025 | Mise à jour généraliste |
| GPT-5.2 | 11 décembre 2025 | Généraliste (actuel) |
| GPT-5.2-Codex | 18 décembre 2025 | Codage spécialisé |
| GPT-5.2-Pro | Décembre 2025 | Raisonnement amélioré |
| GPT-5.3-Codex | 5 février 2026 | Codage spécialisé (dernier) |
Il n'existe pas de modèle généraliste « GPT-5.3 ». La convention de nommage d'OpenAI utilise ici le suffixe .3 exclusivement pour la lignée Codex. Pour les tâches généralistes (rédaction, analyse, conversation), GPT-5.2 reste le modèle le plus récent.
Performances aux benchmarks
GPT-5.3-Codex apporte des améliorations spectaculaires par rapport à son prédécesseur. Tous les scores ci-dessous sont en effort de raisonnement xhigh :
 Résultat de GPT-5.3-Codex sur une tâche de travail intellectuel GDPval conçue par un professionnel expérimenté, Source : OpenAI
Résultat de GPT-5.3-Codex sur une tâche de travail intellectuel GDPval conçue par un professionnel expérimenté, Source : OpenAI
Benchmarks de codage
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 | Amélioration |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 77,3 % | 64,0 % | 62,2 % | +20,8 % |
| SWE-Bench Pro | 56,8 % | 56,4 % | 55,6 % | +0,7 % |
| SWE-Lancer IC Diamond | 81,4 % | 76,0 % | 74,6 % | +7,1 % |
Terminal-Bench 2.0 est le benchmark le plus révélateur, il évalue le codage agentique de bout en bout, incluant la planification, l'exécution, le débogage et l'itération. Un bond de 64,0 % à 77,3 % représente une amélioration de 20,8 % en seulement 7 semaines.
Note d'efficacité SWE-Bench Pro : Selon les graphiques officiels de benchmarks d'OpenAI, GPT-5.3-Codex atteint 57 % de précision sur SWE-Bench Pro en effort xhigh en utilisant seulement ~43 800 tokens de sortie, contre GPT-5.2-Codex atteignant 56 % de précision en effort xhigh avec ~91 700 tokens de sortie, démontrant une efficacité en tokens plus de 2× supérieure pour des performances équivalentes.
 GPT-5.3-Codex atteint une précision supérieure avec significativement moins de tokens sur SWE-Bench Pro, Source : OpenAI
GPT-5.3-Codex atteint une précision supérieure avec significativement moins de tokens sur SWE-Bench Pro, Source : OpenAI
Utilisation d'ordinateur et tâches générales
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 | Amélioration |
|---|---|---|---|---|
| OSWorld-Verified | 64,7 % | 38,2 % | 37,9 % | +69,4 % |
| GDPval (victoires/égalités) | 70,9 % | , | 70,9 % | Égalité |
| Cybersecurity CTF | 77,6 % | 67,4 % | 67,7 % | +15,1 % |
L'amélioration sur OSWorld-Verified est stupéfiante : de 38,2 % à 64,7 %, soit une augmentation de 69,4 %. Ce benchmark teste la capacité du modèle à interagir avec les systèmes d'exploitation, cliquer, naviguer, remplir des formulaires, gérer des fichiers. GPT-5.3-Codex peut désormais automatiser de manière fiable des tâches informatiques complexes. Les humains obtiennent ~72 % sur ce benchmark, ce qui signifie que GPT-5.3-Codex approche les performances humaines.
 Dans OSWorld-Verified, les modèles utilisent la vision pour accomplir diverses tâches informatiques. Les humains obtiennent ~72 %, Source : OpenAI
Dans OSWorld-Verified, les modèles utilisent la vision pour accomplir diverses tâches informatiques. Les humains obtiennent ~72 %, Source : OpenAI
Observations clés
- →Terminal-Bench et OSWorld montrent des gains massifs, suggérant des améliorations fondamentales en planification et exécution
- →SWE-Bench Pro ne montre qu'une amélioration marginale (+0,7 %), indiquant des effets de plafond sur ce benchmark
- →Cybersecurity CTF l'amélioration (+15,1 %) reflète le nouvel entraînement spécialisé sur les vulnérabilités
- →L'égalité GDPval avec GPT-5.2 suggère que le raisonnement généraliste n'a pas changé (attendu pour un modèle centré sur le codage)
Capacités clés
1. Collaboration interactive
Contrairement aux modèles précédents qui travaillaient silencieusement jusqu'à la fin de la tâche, GPT-5.3-Codex fournit des mises à jour fréquentes de progression et permet aux utilisateurs de guider le modèle pendant qu'il travaille.
Exemple de flux de travail :
Utilisateur : "Construis une application de chat en temps réel avec support WebSocket"
GPT-5.3-Codex : "Lancement de la configuration du projet. Je vais créer :
1. Serveur Express avec la bibliothèque ws
2. Frontend React avec auto-reconnexion
3. Persistance des messages avec SQLite
4. Indicateurs de présence des utilisateurs
Configuration de la structure du projet en cours... ████░░░░ 45%
[Mise à jour] Squelette du serveur terminé. Démarrage du gestionnaire WebSocket.
Dois-je ajouter des indicateurs de saisie et des accusés de lecture ?"
Utilisateur : "Oui, ajoute les deux. Ajoute aussi le threading de messages."
GPT-5.3-Codex : "Ajout du support de threading au schéma.
Modification du modèle de messages... ██████░░ 72%"
Ce mode interactif transforme le codage de « soumettre et attendre » en une véritable collaboration.
2. Projets autonomes sur plusieurs jours
GPT-5.3-Codex peut travailler sur des projets complexes de manière autonome pendant des jours, consommant des millions de tokens tout en construisant des applications sophistiquées :
- →Jeux web complexes avec plusieurs niveaux et moteur physique
- →Applications full-stack avec authentification, base de données et déploiement
- →Plateformes API avec documentation et suites de tests
3. Au-delà du code pur
Malgré son nom, GPT-5.3-Codex va au-delà du code :
- →Présentations : Générer des supports de présentation à partir de spécifications
- →Analyse de données : Traiter des jeux de données et produire des insights
- →PRD : Rédiger des documents d'exigences produit
- →Études utilisateurs : Analyser les retours et identifier des tendances
- →Tableaux de bord de métriques : Construire des outils de monitoring et de reporting
4. Efficacité extrême en tokens
OpenAI rapporte que GPT-5.3-Codex consomme moins de tokens que tout modèle antérieur sur les tâches de codage tout en fonctionnant 25 % plus vite. Cela signifie :
- →Latence réduite sur chaque opération
- →Plus de travail accompli dans les limites de contexte
- →Économies par tâche (quand l'API sera disponible)
- →Sessions autonomes plus longues avant épuisement du contexte
Self-bootstrapping : une étape majeure
GPT-5.3-Codex est le premier modèle d'IA ayant contribué à sa propre création. Pendant le développement, OpenAI a utilisé des versions préliminaires du modèle pour :
- →Déboguer les problèmes d'entraînement : le modèle a identifié des problèmes dans sa propre pipeline d'entraînement
- →Gérer le déploiement : les versions préliminaires ont aidé à orchestrer l'infrastructure de déploiement
- →Diagnostiquer les évaluations : le modèle a analysé ses propres résultats de benchmarks pour identifier des axes d'amélioration
Pourquoi c'est important : Le self-bootstrapping représente un pas vers des systèmes d'IA capables d'améliorer leur propre processus de développement. Bien que GPT-5.3-Codex N'atteigne PAS le niveau « High » en auto-amélioration de l'IA (selon le Preparedness Framework d'OpenAI), le fait qu'il ait contribué à sa propre création est une étape majeure dans la méthodologie de développement de l'IA.
Cela se distingue des modèles précédents où les humains effectuaient tout le débogage de l'entraînement. GPT-5.3-Codex démontre que l'IA peut participer de manière significative au cycle de vie du développement de modèles.
Exemples concrets de self-bootstrapping (d'après l'annonce d'OpenAI)
Selon le billet de blog officiel d'OpenAI, voici comment GPT-5.3-Codex a été utilisé pour se construire lui-même :
- →Équipe de recherche : a utilisé Codex pour surveiller et déboguer l'exécution d'entraînement, suivre les tendances tout au long de l'entraînement et construire des applications permettant aux chercheurs de comprendre précisément les différences de comportement
- →Équipe d'ingénierie : a utilisé Codex pour optimiser le harnais, identifier les bugs de rendu de contexte, trouver la cause des faibles taux de hit du cache et dimensionner dynamiquement les clusters GPU lors du lancement
- →Analyse des tests alpha : GPT-5.3-Codex a construit des classifieurs regex pour estimer la fréquence de clarification, les réponses positives/négatives des utilisateurs et la progression des tâches, puis les a exécutés à grande échelle sur tous les journaux de session et a produit des rapports
- →Data science : un data scientist a travaillé avec GPT-5.3-Codex pour construire de nouvelles pipelines de données et visualisations, puis a co-analysé des résultats qui « résumaient de manière concise les insights clés sur des milliers de points de données en moins de trois minutes »
Source : OpenAI
Cybersécurité : première classification « High »
GPT-5.3-Codex est le premier modèle d'IA classé « High » en cybersécurité selon le Preparedness Framework d'OpenAI. C'est également le premier modèle directement entraîné pour identifier les vulnérabilités logicielles.
Ce que signifie « High »
Le Preparedness Framework d'OpenAI catégorise les capacités des modèles sur une échelle de Low à Critical. « High » signifie que le modèle peut :
- →Identifier des vulnérabilités complexes dans du code de production
- →Suggérer des vecteurs d'exploitation pour les vulnérabilités découvertes
- →Analyser les architectures de sécurité pour détecter les faiblesses
- →Réaliser des défis sophistiqués de capture-the-flag (CTF) (score de 77,6 %)
Mesures de sécurité déployées
Étant donné la nature à double usage des capacités de cybersécurité, OpenAI a déployé ce qu'ils décrivent comme leur « stack de sécurité cybersécurité le plus complet à ce jour » :
- →Programme pilote Trusted Access for Cyber : accès contrôlé pour les professionnels de cybersécurité vérifiés afin d'accélérer la recherche en cyberdéfense
- →10 M$ en crédits API : engagés envers les organisations de cyberdéfense, notamment pour les logiciels open source et les infrastructures critiques
- →Expansion d'Aardvark : l'agent de recherche en sécurité d'OpenAI, en expansion de sa bêta privée comme première offre de leur suite de produits Codex Security, déjà utilisé pour trouver des vulnérabilités dans Next.js (CVE-2025-59471 et CVE-2025-59472)
- →Protections du Preparedness Framework : entraînement à la sécurité, surveillance automatisée, pipelines d'application incluant le renseignement sur les menaces
- →Analyse open source : partenariat avec les mainteneurs open source pour l'analyse gratuite des bases de code
 Capacités de cybersécurité de GPT-5.3-Codex et programme Trusted Access, Source : OpenAI
Capacités de cybersécurité de GPT-5.3-Codex et programme Trusted Access, Source : OpenAI
Le dilemme du double usage
Un modèle entraîné pour trouver des vulnérabilités peut aussi être utilisé pour les exploiter. L'approche d'OpenAI consiste à :
- →Rendre le modèle disponible à des fins défensives
- →Restreindre l'accès via le programme Trusted Access
- →Surveiller les schémas d'utilisation pour détecter les abus potentiels
- →Investir massivement dans les applications défensives (engagement de 10 M$)
Cela fait de GPT-5.3-Codex à la fois un outil puissant pour les professionnels de la sécurité et un modèle nécessitant une gouvernance rigoureuse.
Disponibilité et accès
Où accéder à GPT-5.3-Codex
| Plateforme | Disponible | Notes |
|---|---|---|
| ChatGPT (forfaits payants) | ✅ Oui | Plus, Pro, Team, Enterprise |
| Application Codex | ✅ Oui | Application de codage autonome |
| Codex CLI | ✅ Oui | Interface en ligne de commande |
| Extension Codex IDE | ✅ Oui | VS Code et autres |
| Web (codex.openai.com) | ✅ Oui | Accès via navigateur |
| API OpenAI | ❌ Pas encore | « Travaillons à l'activer en toute sécurité » |
Calendrier de l'accès API
Au 6 février 2026, GPT-5.3-Codex n'est PAS disponible via l'API OpenAI. OpenAI déclare travailler à « l'activer en toute sécurité », probablement en raison de la classification « High » en cybersécurité du modèle nécessitant des mesures de sécurité supplémentaires avant un accès programmatique large.
Note d'infrastructure : GPT-5.3-Codex a été co-conçu pour, entraîné avec et servi sur des systèmes NVIDIA GB200 NVL72. OpenAI fait également fonctionner GPT-5.3-Codex 25 % plus vite pour les utilisateurs de Codex grâce à des améliorations de leur infrastructure et de leur stack d'inférence.
Cela signifie :
- →Vous ne pouvez pas intégrer GPT-5.3-Codex dans des applications personnalisées pour le moment
- →Les utilisateurs Enterprise doivent utiliser l'application/CLI/extension Codex
- →Aucun traitement programmatique par lot n'est disponible
- →Les tarifs d'accès API n'ont pas été annoncés
Tarifs
Aucun tarif spécifique n'a été annoncé pour GPT-5.3-Codex. L'accès est actuellement inclus dans les forfaits payants ChatGPT :
- →ChatGPT Plus : 20 $/mois
- →ChatGPT Pro : 200 $/mois (limites d'utilisation supérieures)
- →ChatGPT Team : 25 $/utilisateur/mois
- →ChatGPT Enterprise : Tarification personnalisée
Cas d'usage pratiques
1. Développement d'application full-stack
Prompt : "Construis une API de gestion de tâches avec :
- Backend Express.js avec TypeScript
- PostgreSQL avec Prisma ORM
- Authentification JWT avec refresh tokens
- Contrôle d'accès basé sur les rôles (admin, member, viewer)
- Notifications WebSocket pour les mises à jour de tâches
- Docker Compose pour le développement local
- Suite de tests complète avec Jest"
GPT-5.3-Codex peut construire cela de manière autonome sur une session de plusieurs heures, fournissant des mises à jour tout au long et vous permettant de guider les décisions.
2. Audit de sécurité et évaluation des vulnérabilités
Prompt : "Audite cette application e-commerce Node.js pour :
- Les vulnérabilités du Top 10 OWASP
- Les failles de logique métier
- Les vecteurs de contournement d'authentification
- Les risques d'exposition de données
- Les vulnérabilités des dépendances
Fournis des niveaux de sévérité et des étapes de remédiation."
Avec sa classification « High » en cybersécurité, GPT-5.3-Codex excelle dans les audits de sécurité complets.
3. Modernisation de bases de code héritées
Prompt : "Migre cette application Django Python 2.7 vers :
- Python 3.12 avec des annotations de type partout
- Django 5.x avec des vues asynchrones
- Remplacer les API obsolètes
- Ajouter des tests complets pour chaque module migré
- Maintenir des migrations de base de données rétrocompatibles"
4. Sessions de débogage complexes
Prompt : "Ce système de microservices a des erreurs 502 intermittentes
sous charge. Voici les configurations des services, la configuration nginx et
les logs récents. Identifie la cause racine et implémente un correctif."
La fonctionnalité de collaboration interactive permet au modèle de poser des questions de clarification pendant l'investigation.
5. Développement de jeux
OpenAI met spécifiquement en avant la capacité de GPT-5.3-Codex à construire des jeux complexes de manière autonome pendant des jours, incluant :
- →Logique de jeu multi-niveaux
- →Moteurs physiques
- →Systèmes de gestion d'assets
- →Réseau multijoueur
Limitations
Ce que GPT-5.3-Codex ne peut pas faire
- →Pas d'accès API pour le moment : vous ne pouvez pas intégrer GPT-5.3-Codex par programmation dans des applications personnalisées
- →Non généraliste : pour la rédaction, l'analyse ou la conversation, utilisez GPT-5.2
- →Pas de fenêtre de contexte divulguée : OpenAI n'a pas précisé la taille exacte de la fenêtre de contexte
- →Pas de date de coupure des connaissances publiée : la fraîcheur des données d'entraînement est inconnue
- →Risque de double usage en cybersécurité : la détection de vulnérabilités du modèle peut théoriquement être détournée
- →Auto-amélioration de l'IA plafonnée : N'atteint PAS le niveau « High » en auto-amélioration de l'IA (confirmé par OpenAI)
Plateau SWE-Bench Pro
L'amélioration marginale sur SWE-Bench Pro (56,4 % → 56,8 %) suggère que ce benchmark approche des effets de plafond pour les architectures actuelles. Les améliorations de codage dans le monde réel (captées par Terminal-Bench) sont bien plus significatives.
Incertitude sur les coûts
Sans tarification API, les clients enterprise ne peuvent pas prévoir les coûts pour des déploiements à grande échelle. Cela peut retarder l'adoption par rapport aux concurrents comme Claude Opus 4.6, qui a été lancé avec un accès API complet et une tarification transparente.
GPT-5.3-Codex vs. GPT-5.2-Codex : faut-il migrer ?
| Aspect | GPT-5.3-Codex | GPT-5.2-Codex |
|---|---|---|
| Terminal-Bench 2.0 | 77,3 % | 64,0 % |
| OSWorld | 64,7 % | 38,2 % |
| Cybersecurity CTF | 77,6 % | 67,4 % |
| SWE-Bench Pro | 56,8 % | 56,4 % |
| Vitesse | 25 % plus rapide | Référence |
| Utilisation de tokens | Inférieure | Référence |
| Mises à jour interactives | ✅ Oui | ❌ Non |
| Accès API | ❌ Pas encore | ✅ Oui |
Verdict : Si vous utilisez l'application Codex, le CLI ou l'extension IDE, migrez immédiatement. Les améliorations sur Terminal-Bench (+20,8 %) et OSWorld (+69,4 %) sont massives. Si vous dépendez de l'accès API, vous devrez attendre qu'OpenAI l'active.
FAQ
Quand GPT-5.3 est-il sorti ?
GPT-5.3-Codex est sorti le 5 février 2026.
GPT-5.3 est-il meilleur que ChatGPT 5.2 ?
Pour les tâches de codage et de cybersécurité, oui. GPT-5.3-Codex surpasse significativement GPT-5.2 sur Terminal-Bench (77,3 % vs 62,2 %) et Cybersecurity CTF (77,6 % vs 67,7 %). Pour les tâches généralistes comme la rédaction et la conversation, GPT-5.2 reste le meilleur choix.
Peut-on utiliser GPT-5.3 via l'API ?
Pas encore en février 2026. OpenAI déclare travailler à « l'activer en toute sécurité ». Actuellement, GPT-5.3-Codex est disponible via l'application Codex, le CLI, l'extension IDE et les forfaits payants ChatGPT.
GPT-5.3 est-il sûr à utiliser ?
OpenAI a déployé son « stack de sécurité cybersécurité le plus complet » pour GPT-5.3-Codex. Le modèle est classé « High » en capacité de cybersécurité mais N'atteint PAS le niveau « High » en auto-amélioration de l'IA. Les mesures de sécurité incluent le programme Trusted Access, la surveillance et les restrictions d'utilisation.
Comment GPT-5.3 se compare-t-il à Claude Opus 4.6 ?
Consultez notre comparaison détaillée : Claude Opus 4.6 vs GPT-5.3 Codex. En résumé : GPT-5.3-Codex domine sur Terminal-Bench et l'utilisation d'ordinateur ; Opus 4.6 domine sur le raisonnement général, offre un contexte de 1M, dispose d'un accès API avec tarification transparente et excelle dans le travail intellectuel.
- →Claude Opus 4.6 vs GPT-5.3 Codex, Comparaison directe
- →Guide Claude Opus 4.6, Le nouveau modèle frontier d'Anthropic
- →Guide de prompting ChatGPT 5.2, Maîtriser le modèle généraliste
- →Comparaison des éditeurs de code IA, Benchmarks des IDE
- →Claude Code vs Copilot vs Cursor, Comparaison des outils de codage
Ce qu'il faut retenir
- →
GPT-5.3-Codex est un modèle de codage spécialisé, pas un GPT-5.3 généraliste, le modèle généraliste d'OpenAI reste GPT-5.2
- →
Le score Terminal-Bench 2.0 de 77,3 % représente une amélioration de 20,8 % par rapport à GPT-5.2-Codex, le plus grand gain en une seule génération pour le codage agentique
- →
Premier modèle d'IA « High » en cybersécurité, directement entraîné pour trouver des vulnérabilités, avec des mesures de sécurité complètes
- →
Étape majeure du self-bootstrapping : premier modèle ayant contribué à son propre processus de développement
- →
OSWorld à 64,7 % (contre 38,2 %) montre une amélioration transformatrice des capacités d'utilisation d'ordinateur
- →
25 % plus rapide avec moins de tokens que tout modèle antérieur sur les tâches de codage
- →
Pas d'accès API pour le moment, disponible uniquement via l'application Codex, le CLI, l'extension IDE et les forfaits payants ChatGPT
Construisez des agents IA et des workflows agentiques
Les capacités de codage autonome de GPT-5.3-Codex représentent la frontière de l'IA agentique. Comprendre les principes derrière les agents autonomes, planification, utilisation d'outils, auto-correction, vous aidera à exploiter efficacement ces modèles.
Dans notre Module 6, Agents IA et orchestration, vous apprendrez :
- →Comment les agents IA planifient, raisonnent et agissent de manière autonome
- →Le pattern ReAct pour combiner raisonnement et utilisation d'outils
- →La construction de systèmes multi-agents pour des workflows complexes
- →Les patterns d'intégration d'outils et d'appels de fonctions
- →Les patterns de sécurité pour les systèmes d'IA autonomes
- →Quand utiliser l'IA agentique vs des approches plus simples
→ Explorer le Module 6 : Agents IA et orchestration
Dernière mise à jour : 6 février 2026 Fonctionnalités et spécifications vérifiées d'après le blog officiel d'OpenAI et la documentation de la plateforme.
Module 6 — AI Agents & ReAct
Create autonomous agents that reason and take actions.
Dorian Laurenceau
Full-Stack Developer & Learning DesignerFull-stack web developer and learning designer. I spent 4 years as a freelance full-stack developer and 4 years teaching React, JavaScript, HTML/CSS and WordPress to adult learners. Today I design learning paths in web development and AI, grounded in learning science. I founded learn-prompting.fr to make AI practical and accessible, and built the Bluff app to gamify political transparency.
Weekly AI Insights
Tools, techniques & news — curated for AI practitioners. Free, no spam.
Free, no spam. Unsubscribe anytime.
→Related Articles
FAQ
Qu'est-ce que GPT-5.3 ?+
GPT-5.3 désigne GPT-5.3-Codex, le modèle de codage agentique spécialisé d'OpenAI sorti le 5 février 2026. Ce n'est pas un modèle généraliste, il est conçu spécifiquement pour la génération de code autonome, le débogage et la cybersécurité. Il n'existe pas de modèle généraliste « GPT-5.3 » distinct.
GPT-5.3 est-il un modèle généraliste comme GPT-5.2 ?+
Non. GPT-5.3-Codex est un modèle de codage spécialisé, pas un successeur généraliste de GPT-5.2. Le modèle généraliste actuel d'OpenAI reste GPT-5.2. GPT-5.3-Codex est optimisé spécifiquement pour le codage agentique, le débogage et les tâches de cybersécurité.
Quel est le score Terminal-Bench de GPT-5.3-Codex ?+
GPT-5.3-Codex obtient 77,3 % sur Terminal-Bench 2.0 en effort de raisonnement xhigh, une amélioration majeure par rapport aux 64,0 % de GPT-5.2-Codex et aux 62,2 % de GPT-5.2.
Pourquoi GPT-5.3-Codex est-il considéré comme dangereux pour la cybersécurité ?+
GPT-5.3-Codex est le premier modèle d'IA classé « High » en cybersécurité selon le Preparedness Framework d'OpenAI, et le premier directement entraîné pour identifier les vulnérabilités logicielles. OpenAI a déployé des mesures de sécurité complètes incluant un programme Trusted Access.
Combien coûte GPT-5.3 Codex ?+
GPT-5.3-Codex est disponible sur les forfaits payants ChatGPT, l'application Codex, Codex CLI et l'extension Codex IDE. L'accès API n'est pas encore disponible en février 2026, OpenAI déclare travailler à « l'activer en toute sécurité » prochainement.
Qu'est-ce que le self-bootstrapping dans GPT-5.3-Codex ?+
GPT-5.3-Codex est le premier modèle ayant joué un rôle clé dans sa propre création. OpenAI a utilisé des versions préliminaires du modèle pour déboguer son propre processus d'entraînement, gérer le déploiement et diagnostiquer les problèmes d'évaluation, une étape majeure dans l'auto-amélioration de l'IA.
Comment GPT-5.3 se compare-t-il à Claude Opus 4.6 ?+
Les deux ont été lancés le 5 février 2026. GPT-5.3-Codex domine sur Terminal-Bench 2.0 (77,3 %) et OSWorld (64,7 %). Claude Opus 4.6 offre des capacités plus larges avec un contexte de 1M, des tarifs inférieurs (5$/25$ via API) et un raisonnement général plus fort. GPT-5.3-Codex n'a pas encore d'accès API.
GPT-5.3-Codex peut-il travailler sur des tâches non liées au code ?+
Oui, malgré son nom. OpenAI rapporte que GPT-5.3-Codex peut créer des présentations, effectuer des analyses de données, rédiger des PRD, mener des études utilisateurs et analyser des métriques, bien qu'il soit principalement optimisé pour les flux de travail de codage.