GPT-5.3 Codex: Complete Guide, Benchmarks & How to Use It (2026)
By Learnia Team
GPT-5.3 Codex: OpenAI's Most Powerful Agentic Coding Model (2026)
This article is written in English. Our training modules are available in multiple languages.
📅 Last Updated: February 6, 2026 — Released February 5, 2026.
📚 Related: GPT-5.2 Codex Deep Dive | Claude Opus 4.6 vs GPT-5.3 Codex | AI Code Editors Comparison | ChatGPT 5.2 Prompting Guide
Table of Contents
- →What Is GPT-5.3-Codex?
- →GPT-5.3 vs GPT-5.3-Codex: Clarification
- →Benchmark Performance
- →Key Capabilities
- →Self-Bootstrapping: A Milestone
- →Cybersecurity: First "High" Rating
- →Availability & Access
- →Practical Use Cases
- →Limitations
- →FAQ
On February 5, 2026, OpenAI released GPT-5.3-Codex — their most powerful agentic coding model. This is not an incremental update: GPT-5.3-Codex is the first AI model rated "High" capability in cybersecurity under OpenAI's Preparedness Framework, the first model directly trained to identify software vulnerabilities, and the first model instrumental in creating itself through self-bootstrapping.
Important clarification: There is no standalone "GPT-5.3" general-purpose model. What people refer to as "GPT 5.3" is specifically GPT-5.3-Codex — a specialized model optimized for coding, debugging, and cybersecurity. OpenAI's current general-purpose model remains GPT-5.2.
With a 77.3% score on Terminal-Bench 2.0 (up from 64.0% for its predecessor), a 64.7% on OSWorld-Verified (up from 38.2%), and a first-of-its-kind cybersecurity classification, GPT-5.3-Codex represents a step change in what AI coding agents can do. In this guide, we'll cover everything: benchmarks, capabilities, safety implications, and how to access it.
Learn AI — From Prompts to Agents
What Is GPT-5.3-Codex?
GPT-5.3-Codex is OpenAI's purpose-built agentic coding model, the successor to GPT-5.2-Codex released December 18, 2025. It is designed to autonomously plan, write, debug, and deploy code across complex multi-file projects with minimal human intervention.
Key definition: GPT-5.3-Codex is a specialized agentic AI model released February 5, 2026, optimized for autonomous software development, cybersecurity analysis, and computer use — running 25% faster than its predecessor while consuming fewer tokens per task.
Technical Specifications
| Specification | GPT-5.3-Codex | GPT-5.2-Codex (previous) |
|---|---|---|
| Release Date | February 5, 2026 | December 18, 2025 |
| Type | Specialized coding agent | Specialized coding agent |
| Training Hardware | NVIDIA GB200 NVL72 | Not disclosed |
| Speed | 25% faster than predecessor | Baseline |
| Token Efficiency | Fewer tokens than any prior model | Baseline |
| Cybersecurity Rating | High (first ever) | Medium |
| Biology Rating | High | High |
| Self-Improvement | Does NOT reach High | N/A |
| API Access | ❌ Not yet available | ✅ Available |
| ChatGPT Access | ✅ Paid plans | ✅ Paid plans |
GPT-5.3 vs GPT-5.3-Codex: Clarification
If you searched for "GPT 5.3" expecting a new general-purpose model — here's what you need to know:
The GPT-5.x model family timeline:
| Model | Release Date | Type |
|---|---|---|
| GPT-5 | August 7, 2025 | General-purpose |
| GPT-5.1 | November 12, 2025 | General-purpose update |
| GPT-5.2 | December 11, 2025 | General-purpose (current) |
| GPT-5.2-Codex | December 18, 2025 | Specialized coding |
| GPT-5.2-Pro | December 2025 | Enhanced reasoning |
| GPT-5.3-Codex | February 5, 2026 | Specialized coding (latest) |
There is no "GPT-5.3" general model. OpenAI's naming convention uses the .3 suffix exclusively for the Codex line here. For general-purpose tasks (writing, analysis, conversation), GPT-5.2 remains the latest model.
Benchmark Performance
GPT-5.3-Codex delivers dramatic improvements over its predecessor. All scores below are at xhigh reasoning effort:
 GPT-5.3-Codex output on a GDPval knowledge work task designed by an experienced professional — Source: OpenAI
GPT-5.3-Codex output on a GDPval knowledge work task designed by an experienced professional — Source: OpenAI
Coding Benchmarks
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 | Improvement |
|---|---|---|---|---|
| Terminal-Bench 2.0 | 77.3% | 64.0% | 62.2% | +20.8% |
| SWE-Bench Pro | 56.8% | 56.4% | 55.6% | +0.7% |
| SWE-Lancer IC Diamond | 81.4% | 76.0% | 74.6% | +7.1% |
Terminal-Bench 2.0 is the most telling benchmark — it evaluates end-to-end agentic coding including planning, execution, debugging, and iteration. A jump from 64.0% to 77.3% represents a 20.8% improvement in just 7 weeks.
SWE-Bench Pro efficiency note: According to OpenAI's official benchmark charts, GPT-5.3-Codex achieves 57% accuracy on SWE-Bench Pro at xhigh effort using only ~43,800 output tokens, compared to GPT-5.2-Codex reaching 56% accuracy at xhigh effort using ~91,700 output tokens — demonstrating over 2× token efficiency for equivalent performance.
 GPT-5.3-Codex achieves higher accuracy with significantly fewer tokens on SWE-Bench Pro — Source: OpenAI
GPT-5.3-Codex achieves higher accuracy with significantly fewer tokens on SWE-Bench Pro — Source: OpenAI
Computer Use & General Tasks
| Benchmark | GPT-5.3-Codex | GPT-5.2-Codex | GPT-5.2 | Improvement |
|---|---|---|---|---|
| OSWorld-Verified | 64.7% | 38.2% | 37.9% | +69.4% |
| GDPval (wins/ties) | 70.9% | — | 70.9% | Tied |
| Cybersecurity CTF | 77.6% | 67.4% | 67.7% | +15.1% |
The OSWorld-Verified improvement is staggering: from 38.2% to 64.7%, a 69.4% increase. This benchmark tests the model's ability to interact with operating systems — clicking, navigating, filling forms, managing files. GPT-5.3-Codex can now reliably automate complex computer tasks. Humans score ~72% on this benchmark, meaning GPT-5.3-Codex is approaching human-level performance.
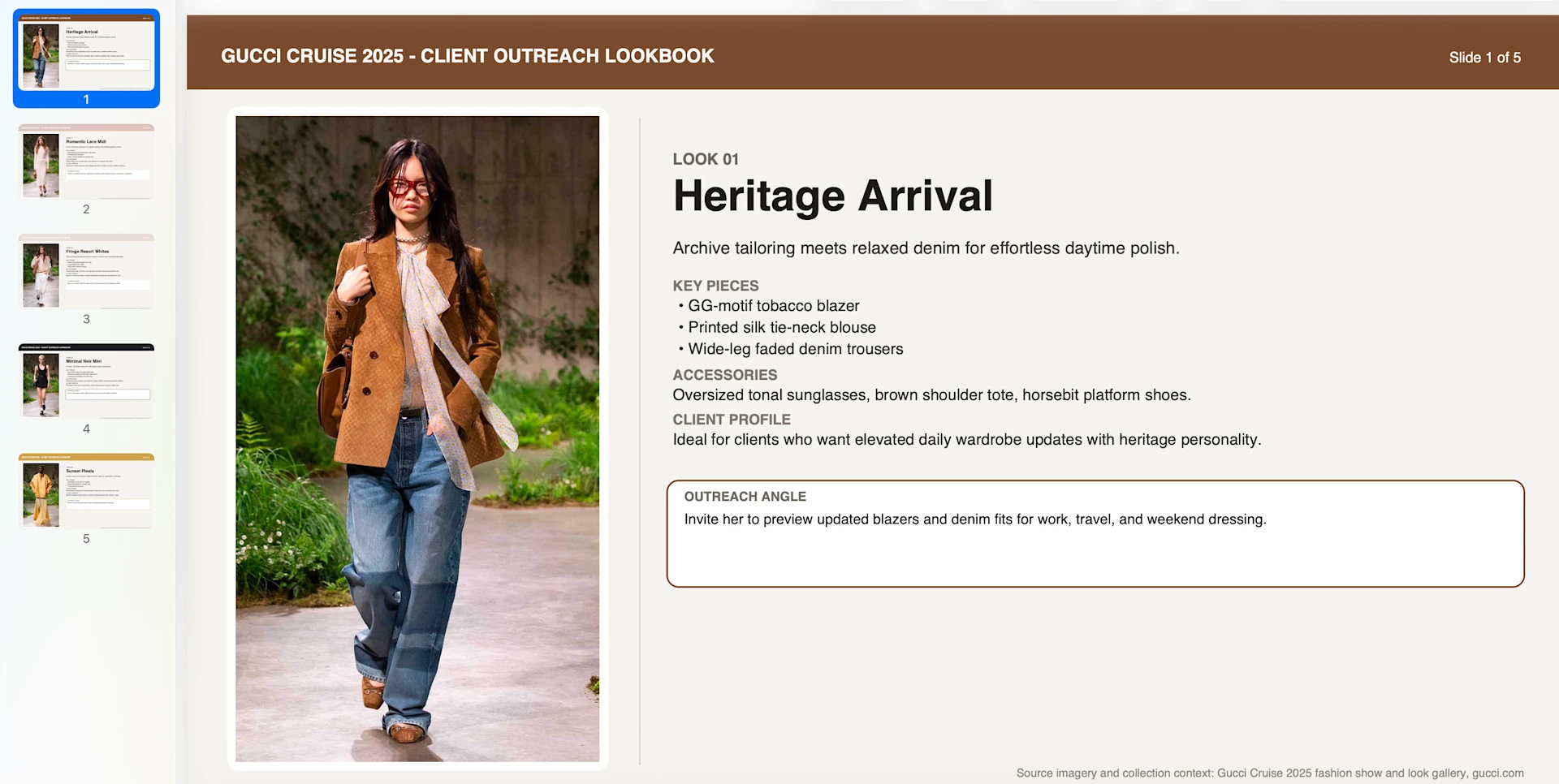 In OSWorld-Verified, models use vision to complete diverse computer tasks. Humans score ~72% — Source: OpenAI
In OSWorld-Verified, models use vision to complete diverse computer tasks. Humans score ~72% — Source: OpenAI
Key Observations
- →Terminal-Bench and OSWorld show massive gains, suggesting fundamental improvements in planning and execution
- →SWE-Bench Pro shows only marginal improvement (+0.7%), indicating ceiling effects on this benchmark
- →Cybersecurity CTF improvement (+15.1%) reflects the new specialized vulnerability training
- →GDPval tie with GPT-5.2 suggests general-purpose reasoning hasn't changed (expected for a coding-focused model)
Key Capabilities
1. Interactive Collaboration
Unlike previous models that worked silently until task completion, GPT-5.3-Codex provides frequent progress updates and allows users to steer the model while it works.
Example workflow:
User: "Build a real-time chat application with WebSocket support"
GPT-5.3-Codex: "Starting project setup. I'll create:
1. Express server with ws library
2. React frontend with auto-reconnection
3. Message persistence with SQLite
4. User presence indicators
Setting up project structure now... ████░░░░ 45%
[Update] Server scaffold complete. Starting WebSocket handler.
Should I add typing indicators and read receipts?"
User: "Yes, add both. Also add message threading."
GPT-5.3-Codex: "Adding threading support to the schema.
Modifying message model... ██████░░ 72%"
This interactive pattern transforms coding from "submit and wait" to genuine collaboration.
2. Autonomous Multi-Day Projects
GPT-5.3-Codex can work on complex projects autonomously over days, consuming millions of tokens while building sophisticated applications:
- →Complex web games with multiple levels and physics
- →Full-stack applications with authentication, database, and deployment
- →API platforms with documentation and test suites
3. Beyond Pure Coding
Despite its name, GPT-5.3-Codex extends beyond code:
- →Slide decks: Generate presentation materials from specs
- →Data analysis: Process datasets and produce insights
- →PRDs: Write product requirement documents
- →User research: Analyze feedback and identify patterns
- →Metrics dashboards: Build monitoring and reporting tools
4. Extreme Token Efficiency
OpenAI reports that GPT-5.3-Codex consumes fewer tokens than any prior model on coding tasks while running 25% faster. This means:
- →Lower latency on each operation
- →More work done within context limits
- →Cost savings per task (when API becomes available)
- →Longer autonomous sessions before context exhaustion
Self-Bootstrapping: A Milestone
GPT-5.3-Codex is the first AI model instrumental in creating itself. During development, OpenAI used early versions of the model to:
- →Debug training issues: The model identified problems in its own training pipeline
- →Manage deployment: Early versions helped orchestrate the deployment infrastructure
- →Diagnose evaluations: The model analyzed its own benchmark results to identify improvement areas
Why this matters: Self-bootstrapping represents a step toward AI systems that can improve their own development process. While GPT-5.3-Codex does NOT reach "High" capability on AI self-improvement (according to OpenAI's Preparedness Framework), the fact that it contributed to its own creation is a milestone in AI development methodology.
This is distinct from previous models where humans did all the training debugging. GPT-5.3-Codex demonstrates that AI can meaningfully participate in the model development lifecycle.
Concrete Self-Bootstrapping Examples (from OpenAI's announcement)
According to OpenAI's official blog post, here's how GPT-5.3-Codex was used to build itself:
- →Research team: Used Codex to monitor and debug the training run, track patterns throughout training, and build applications for researchers to precisely understand behavior differences
- →Engineering team: Used Codex to optimize the harness, identify context rendering bugs, root cause low cache hit rates, and dynamically scale GPU clusters during launch
- →Alpha testing analysis: GPT-5.3-Codex built regex classifiers to estimate clarification frequency, positive/negative user responses, and task progress — then ran them scalably over all session logs and produced reports
- →Data science: A data scientist worked with GPT-5.3-Codex to build new data pipelines and visualizations, then co-analyzed results that "concisely summarized key insights over thousands of data points in under three minutes"
Source: OpenAI
Cybersecurity: First "High" Rating
GPT-5.3-Codex is the first AI model classified as "High" capability in cybersecurity under OpenAI's Preparedness Framework. It is also the first model directly trained to identify software vulnerabilities.
What "High" Means
OpenAI's Preparedness Framework categorizes model capabilities on a scale from Low to Critical. "High" means the model can:
- →Identify complex vulnerabilities in production code
- →Suggest exploitation vectors for discovered vulnerabilities
- →Analyze security architectures for weaknesses
- →Perform sophisticated capture-the-flag (CTF) challenges (77.6% score)
Safety Measures Deployed
Given the dual-use nature of cybersecurity capabilities, OpenAI has deployed what they describe as their "most comprehensive cybersecurity safety stack to date":
- →Trusted Access for Cyber pilot program: Controlled access for vetted cybersecurity professionals to accelerate cyber defense research
- →$10M in API credits: Committed to cyber defense organizations, especially for open source software and critical infrastructure
- →Aardvark expansion: OpenAI's security research agent, expanding private beta as the first offering in their Codex Security products suite — already used to find vulnerabilities in Next.js (CVE-2025-59471 and CVE-2025-59472)
- →Preparedness Framework safeguards: Safety training, automated monitoring, enforcement pipelines including threat intelligence
- →Open-source scanning: Partnering with open-source maintainers for free codebase scanning
 GPT-5.3-Codex cybersecurity capabilities and Trusted Access program — Source: OpenAI
GPT-5.3-Codex cybersecurity capabilities and Trusted Access program — Source: OpenAI
The Dual-Use Dilemma
A model trained to find vulnerabilities can also be used to exploit them. OpenAI's approach is to:
- →Make the model available for defensive purposes
- →Restrict access through the Trusted Access program
- →Monitor usage patterns for potential abuse
- →Invest heavily in defensive applications ($10M commitment)
This makes GPT-5.3-Codex both a powerful tool for security professionals and a model that requires careful governance.
Availability & Access
Where to Access GPT-5.3-Codex
| Platform | Available | Notes |
|---|---|---|
| ChatGPT (Paid plans) | ✅ Yes | Plus, Pro, Team, Enterprise |
| Codex App | ✅ Yes | Standalone coding application |
| Codex CLI | ✅ Yes | Command-line interface |
| Codex IDE Extension | ✅ Yes | VS Code and others |
| Web (codex.openai.com) | ✅ Yes | Browser-based access |
| OpenAI API | ❌ Not yet | "Working to safely enable soon" |
API Access Timeline
As of February 6, 2026, GPT-5.3-Codex is NOT available via the OpenAI API. OpenAI states they are "working to safely enable" API access, likely due to the model's "High" cybersecurity rating requiring additional safety measures before broad programmatic access.
Infrastructure note: GPT-5.3-Codex was co-designed for, trained with, and served on NVIDIA GB200 NVL72 systems. OpenAI is also running GPT-5.3-Codex 25% faster for Codex users thanks to improvements in their infrastructure and inference stack.
This means:
- →You cannot integrate GPT-5.3-Codex into custom applications yet
- →Enterprise users must use the Codex app/CLI/extension
- →No programmatic batch processing is available
- →Pricing for API access has not been announced
Pricing
No specific pricing has been announced for GPT-5.3-Codex. Access is currently bundled with paid ChatGPT plans:
- →ChatGPT Plus: $20/month
- →ChatGPT Pro: $200/month (higher usage limits)
- →ChatGPT Team: $25/user/month
- →ChatGPT Enterprise: Custom pricing
Practical Use Cases
1. Full-Stack Application Development
Prompt: "Build a task management API with:
- Express.js backend with TypeScript
- PostgreSQL with Prisma ORM
- JWT authentication with refresh tokens
- Role-based access control (admin, member, viewer)
- WebSocket notifications for task updates
- Docker Compose for local development
- Comprehensive test suite with Jest"
GPT-5.3-Codex can autonomously build this over a multi-hour session, providing updates throughout and allowing you to steer decisions.
2. Security Audit & Vulnerability Assessment
Prompt: "Audit this Node.js e-commerce application for:
- OWASP Top 10 vulnerabilities
- Business logic flaws
- Authentication bypass vectors
- Data exposure risks
- Dependency vulnerabilities
Provide severity ratings and remediation steps."
With its "High" cybersecurity rating, GPT-5.3-Codex excels at comprehensive security audits.
3. Legacy Codebase Modernization
Prompt: "Migrate this Python 2.7 Django 1.x application to:
- Python 3.12 with type hints throughout
- Django 5.x with async views
- Replace deprecated APIs
- Add comprehensive tests for each migrated module
- Maintain backwards-compatible database migrations"
4. Complex Debugging Sessions
Prompt: "This microservices system has intermittent 502 errors
under load. Here are the service configs, nginx setup, and
recent logs. Identify the root cause and implement a fix."
The interactive collaboration feature allows the model to ask clarifying questions during investigation.
5. Game Development
OpenAI specifically highlights GPT-5.3-Codex's ability to build complex games autonomously over days, including:
- →Multi-level game logic
- →Physics engines
- →Asset management systems
- →Multiplayer networking
Limitations
What GPT-5.3-Codex Cannot Do
- →No API access yet: You cannot programmatically integrate GPT-5.3-Codex into custom applications
- →Not general-purpose: For writing, analysis, or conversation, use GPT-5.2
- →No disclosed context window: OpenAI hasn't specified the exact context window size
- →No knowledge cutoff published: Training data recency is unknown
- →Cybersecurity dual-use risk: The model's vulnerability detection can theoretically be misused
- →AI self-improvement capped: Does NOT reach "High" on AI self-improvement (confirmed by OpenAI)
SWE-Bench Pro Plateau
The marginal improvement on SWE-Bench Pro (56.4% → 56.8%) suggests this benchmark may be approaching ceiling effects for current architectures. Real-world coding improvements (captured by Terminal-Bench) are much more significant.
Cost Uncertainty
Without API pricing, enterprise customers cannot forecast costs for large-scale deployments. This may delay adoption compared to competitors like Claude Opus 4.6, which launched with full API access and transparent pricing.
GPT-5.3-Codex vs. GPT-5.2-Codex: Should You Upgrade?
| Aspect | GPT-5.3-Codex | GPT-5.2-Codex |
|---|---|---|
| Terminal-Bench 2.0 | 77.3% | 64.0% |
| OSWorld | 64.7% | 38.2% |
| Cybersecurity CTF | 77.6% | 67.4% |
| SWE-Bench Pro | 56.8% | 56.4% |
| Speed | 25% faster | Baseline |
| Token Usage | Lower | Baseline |
| Interactive Updates | ✅ Yes | ❌ No |
| API Access | ❌ Not yet | ✅ Yes |
Verdict: If you use the Codex app, CLI, or IDE extension — upgrade immediately. The improvements in Terminal-Bench (+20.8%) and OSWorld (+69.4%) are massive. If you rely on API access, you'll need to wait until OpenAI enables it.
FAQ
When was GPT-5.3 released?
GPT-5.3-Codex was released on February 5, 2026.
Is GPT-5.3 better than ChatGPT 5.2?
For coding and cybersecurity tasks, yes. GPT-5.3-Codex significantly outperforms GPT-5.2 on Terminal-Bench (77.3% vs 62.2%) and Cybersecurity CTF (77.6% vs 67.7%). For general-purpose tasks like writing and conversation, GPT-5.2 remains the better choice.
Can I use GPT-5.3 via API?
Not yet as of February 2026. OpenAI states they are "working to safely enable" API access. Currently, GPT-5.3-Codex is available through the Codex app, CLI, IDE extension, and paid ChatGPT plans.
Is GPT-5.3 safe to use?
OpenAI has deployed their "most comprehensive cybersecurity safety stack" for GPT-5.3-Codex. The model is classified "High" in cybersecurity capability but does NOT reach "High" on AI self-improvement. Safety measures include the Trusted Access program, monitoring, and usage restrictions.
How does GPT-5.3 compare to Claude Opus 4.6?
See our detailed comparison: Claude Opus 4.6 vs GPT-5.3 Codex. In short: GPT-5.3-Codex leads on Terminal-Bench and computer use; Opus 4.6 leads on general reasoning, offers 1M context, has API access with transparent pricing, and excels at knowledge work.
Related Articles
- →GPT-5.2 Codex Deep Dive — Previous model analysis
- →Claude Opus 4.6 vs GPT-5.3 Codex — Head-to-head comparison
- →Claude Opus 4.6 Guide — Anthropic's new frontier model
- →ChatGPT 5.2 Prompting Guide — Master the general-purpose model
- →AI Code Editors Comparison — IDE benchmarks
- →Claude Code vs Copilot vs Cursor — Coding tool comparison
Key Takeaways
- →
GPT-5.3-Codex is a specialized coding model, not a general-purpose GPT-5.3 — OpenAI's general model remains GPT-5.2
- →
Terminal-Bench 2.0 score of 77.3% represents a 20.8% improvement over GPT-5.2-Codex, the largest single-generation gain in agentic coding
- →
First "High" cybersecurity AI model — directly trained to find vulnerabilities, with comprehensive safety measures
- →
Self-bootstrapping milestone: First model that contributed to its own development process
- →
OSWorld 64.7% (from 38.2%) shows transformative improvement in computer use capabilities
- →
25% faster with fewer tokens than any prior model on coding tasks
- →
No API access yet — available only through Codex app, CLI, IDE extension, and ChatGPT paid plans
Build AI Agents and Agentic Workflows
GPT-5.3-Codex's autonomous coding capabilities represent the frontier of agentic AI. Understanding the principles behind autonomous agents — planning, tool use, self-correction — will help you leverage these models effectively.
In our Module 6 — AI Agents & Orchestration, you'll learn:
- →How AI agents plan, reason, and take action autonomously
- →The ReAct pattern for combining reasoning with tool use
- →Building multi-agent systems for complex workflows
- →Tool integration and function calling patterns
- →Safety patterns for autonomous AI systems
- →When to use agentic AI vs. simpler approaches
→ Explore Module 6: AI Agents & Orchestration
Last Updated: February 6, 2026 Features and specifications verified against OpenAI's official blog and platform documentation.
Module 6 — AI Agents & ReAct
Create autonomous agents that reason and take actions.
Weekly AI Insights
Tools, techniques & news — curated for AI practitioners. Free, no spam.
Free, no spam. Unsubscribe anytime.
→Related Articles
FAQ
What is GPT-5.3?+
GPT-5.3 refers to GPT-5.3-Codex, OpenAI's specialized agentic coding model released February 5, 2026. It is not a general-purpose model — it is designed specifically for autonomous code generation, debugging, and cybersecurity. There is no standalone 'GPT-5.3' general model.
Is GPT-5.3 a general-purpose model like GPT-5.2?+
No. GPT-5.3-Codex is a specialized coding model, not a general-purpose successor to GPT-5.2. OpenAI's current general-purpose model remains GPT-5.2. GPT-5.3-Codex is optimized specifically for agentic coding, debugging, and cybersecurity tasks.
What is the GPT-5.3-Codex Terminal-Bench score?+
GPT-5.3-Codex scores 77.3% on Terminal-Bench 2.0 at xhigh reasoning effort, a major improvement over GPT-5.2-Codex's 64.0% and GPT-5.2's 62.2%.
Why is GPT-5.3-Codex considered dangerous for cybersecurity?+
GPT-5.3-Codex is the first AI model rated 'High' capability in cybersecurity under OpenAI's Preparedness Framework, and the first directly trained to identify software vulnerabilities. OpenAI has deployed comprehensive safety measures including a Trusted Access program.
How much does GPT-5.3 Codex cost?+
GPT-5.3-Codex is available on paid ChatGPT plans, the Codex app, Codex CLI, and Codex IDE extension. API access is not yet available as of February 2026 — OpenAI states they are 'working to safely enable' it soon.
What is self-bootstrapping in GPT-5.3-Codex?+
GPT-5.3-Codex is the first model that was instrumental in creating itself. OpenAI used early versions of the model to debug its own training process, manage deployment, and diagnose evaluation issues — a milestone in AI self-improvement.
How does GPT-5.3 compare to Claude Opus 4.6?+
Both were released on February 5, 2026. GPT-5.3-Codex leads on Terminal-Bench 2.0 (77.3%) and OSWorld (64.7%). Claude Opus 4.6 offers broader capabilities with 1M context, lower pricing ($5/$25 via API), and stronger general reasoning. GPT-5.3-Codex has no API access yet.
Can GPT-5.3-Codex work on non-coding tasks?+
Yes, despite its name. OpenAI reports GPT-5.3-Codex can create slide decks, perform data analysis, write PRDs, conduct user research, and analyze metrics — though it's primarily optimized for coding workflows.