Claude Opus 4.6 vs GPT-5.3 Codex: Which AI Coding Model
By Dorian Laurenceau
📅 Last reviewed: April 24, 2026. Updated with April 2026 findings and community feedback.
Claude Opus 4.6 vs GPT-5.3 Codex: Which AI Coding Model Wins in 2026?
📅 Last Updated: February 6, 2026, Both models released February 5, 2026.
📚 Related: Claude Opus 4.6 Guide | GPT-5.3 Codex Guide | LLM Benchmarks 2026 | AI Code Editors Comparison
February 5, 2026 was a landmark day for AI: both Anthropic and OpenAI released their most powerful models simultaneously. Claude Opus 4.6 brought a 1 million token context window and adaptive thinking. GPT-5.3-Codex introduced the first "High" cybersecurity rating and self-bootstrapping.
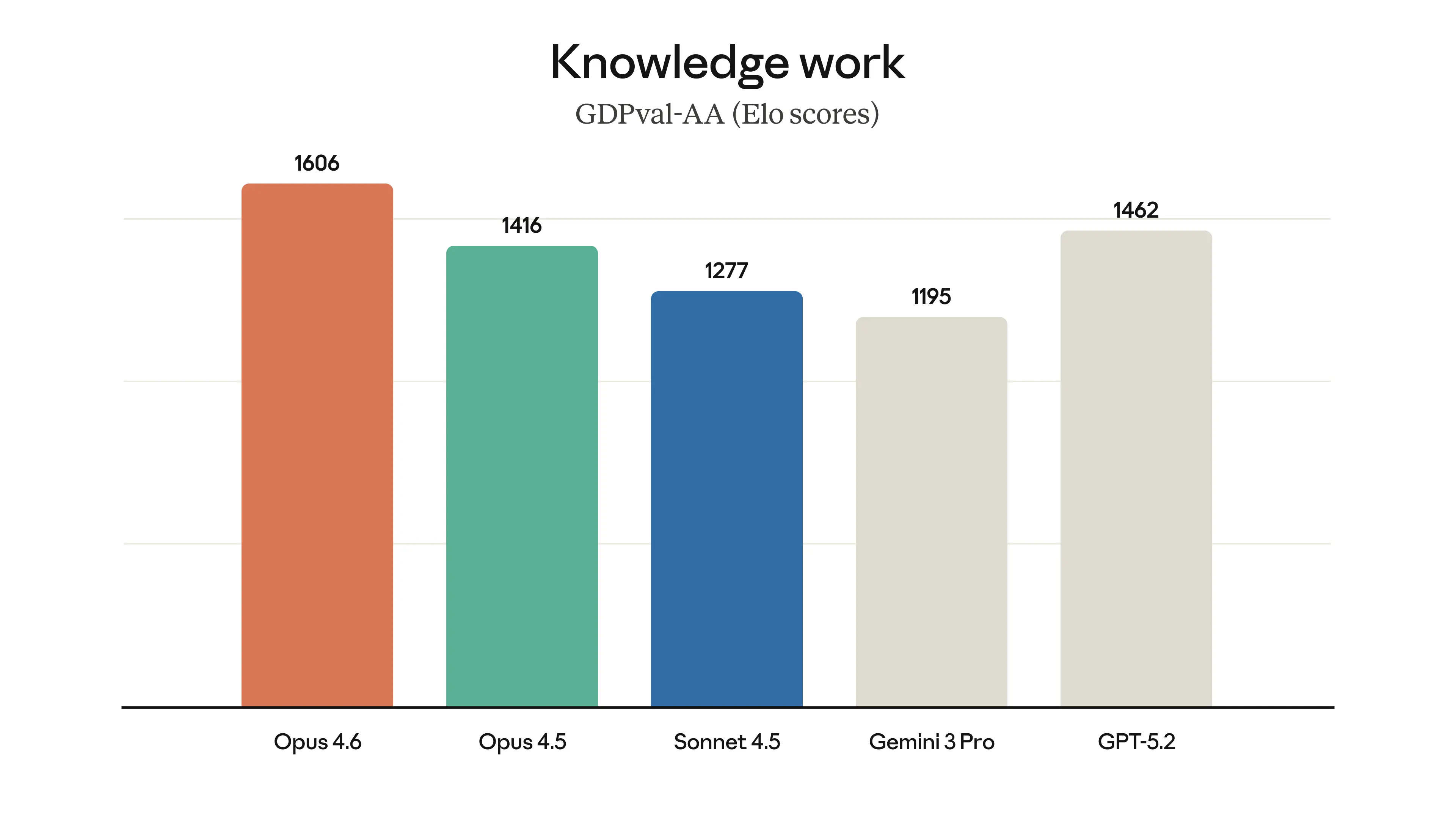 Claude Opus 4.6 GDPval-AA benchmark results, Source: Anthropic
Claude Opus 4.6 GDPval-AA benchmark results, Source: Anthropic
 GPT-5.3-Codex performing a GDPval knowledge work task, Source: OpenAI
GPT-5.3-Codex performing a GDPval knowledge work task, Source: OpenAI
But which one should you actually use? The answer depends entirely on your use case. In this data-driven comparison, we'll break down every dimension that matters, with benchmark scores, feature tables, and clear verdicts for each scenario.
The Contenders
The honest frame for any "Claude vs GPT" comparison in 2026, as the long-running r/ChatGPTCoding, r/OpenAI, and r/ClaudeAI megathreads keep documenting: the benchmarks are close enough that choice of model usually comes down to which failure modes you can tolerate, not which scores are higher. Opus 4.6 tends to be more deliberate and more willing to say "I don't know"; GPT-5.3 Codex tends to produce more code faster with more self-confidence. Both are correct most of the time, wrong in different ways, and improving month-over-month. The LMArena leaderboard, LiveBench, and SWE-Bench Verified are the three benchmarks worth tracking; most others are saturated.
Where the community correctly pushes back on the vs-posts: your workload is not the benchmark. A model that wins on HumanEval by three points can still be worse for your codebase if it doesn't match your style, your framework, or your review culture. Teams that migrate between frontier models on every launch typically discover the real cost is prompt rewriting, eval rebuilding, and cache invalidation — often several weeks of engineering time to recover the productivity they had before the switch.
The pragmatic rule: pick one frontier model as your daily driver, keep a second available for A/B checks on hard prompts, and re-evaluate seriously (with your own eval set, not Twitter) once per quarter. Anything more frequent is thrash, not optimization.
Benchmark Comparison
Let's compare the hard numbers. Note: these models use different benchmark suites, making direct comparison challenging. We'll present what's available for each.
Coding Benchmarks
Reasoning & General Benchmarks
The Benchmark Reality
Three important observations:
- →Different evaluation suites make apples-to-apples comparison impossible for most benchmarks
- →Terminal-Bench 2.0 is the only benchmark where both models claim top performance, but Anthropic hasn't published an exact number for Opus 4.6
- →Claude Opus 4.6 has far more published benchmark data than GPT-5.3-Codex, which is typical for Anthropic's detailed system cards vs. OpenAI's more selective disclosure
Agentic Coding
Both models are built for autonomous, multi-step coding tasks, but they approach it very differently.
Claude Opus 4.6: Agent Teams + 1M Context
Opus 4.6's coding approach centers on breadth and parallelism:
- →Agent Teams (Research Preview): Spawn multiple Claude Code agents working in parallel on the same codebase
- →1M token context: Understand entire medium-to-large codebases in one session
- →Context compaction: Automatically summarize older context to extend session duration
- →Careful planning: Creates detailed execution plans before making changes
Best for: Large codebases, architectural refactoring, multi-day projects requiring deep understanding of the entire system.
GPT-5.3-Codex: Speed + Interactive Collaboration
GPT-5.3-Codex's approach centers on speed and interactivity:
- →25% faster than predecessor with fewer tokens per task
- →Interactive updates: Provides progress reports and allows steering during execution
- →Autonomous multi-day projects: Can work on complex applications over days
- →Self-correcting: Trained to identify and fix its own bugs
Best for: Greenfield development, rapid prototyping, projects where real-time collaboration is valued.
Long Context
This is where the models diverge most dramatically.
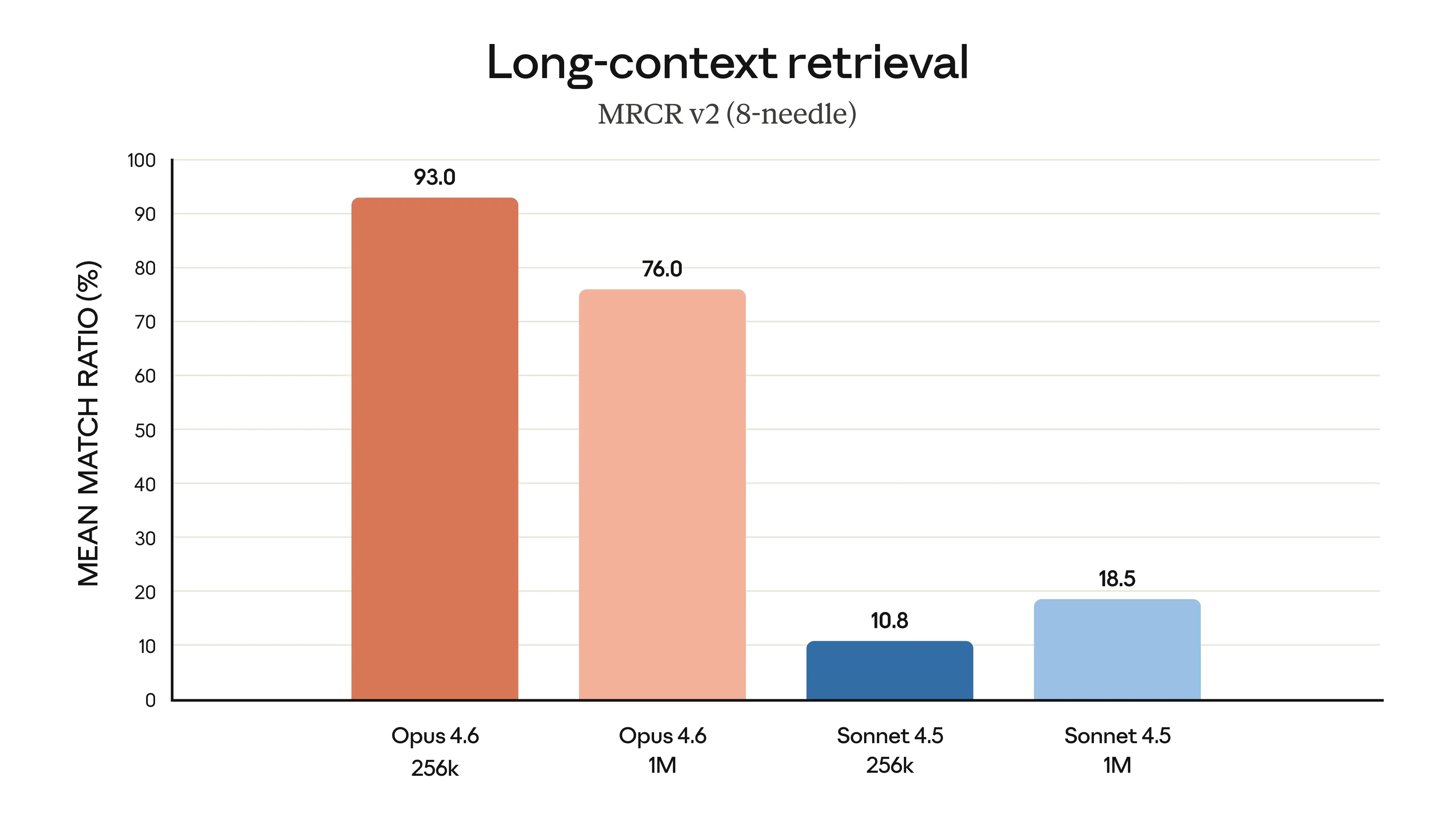 Claude Opus 4.6 shows significant improvement in long-context retrieval, Source: Anthropic
Claude Opus 4.6 shows significant improvement in long-context retrieval, Source: Anthropic
Verdict: Claude Opus 4.6 wins decisively. With a verified 1M context window and 76% MRCR retrieval, Opus 4.6 sets a new standard for long-context AI. GPT-5.3-Codex hasn't disclosed its context window size, making comparison impossible, but Opus 4.6's transparency here is itself an advantage.
Cybersecurity
Both models claim exceptional cybersecurity capabilities, but with fundamentally different approaches.
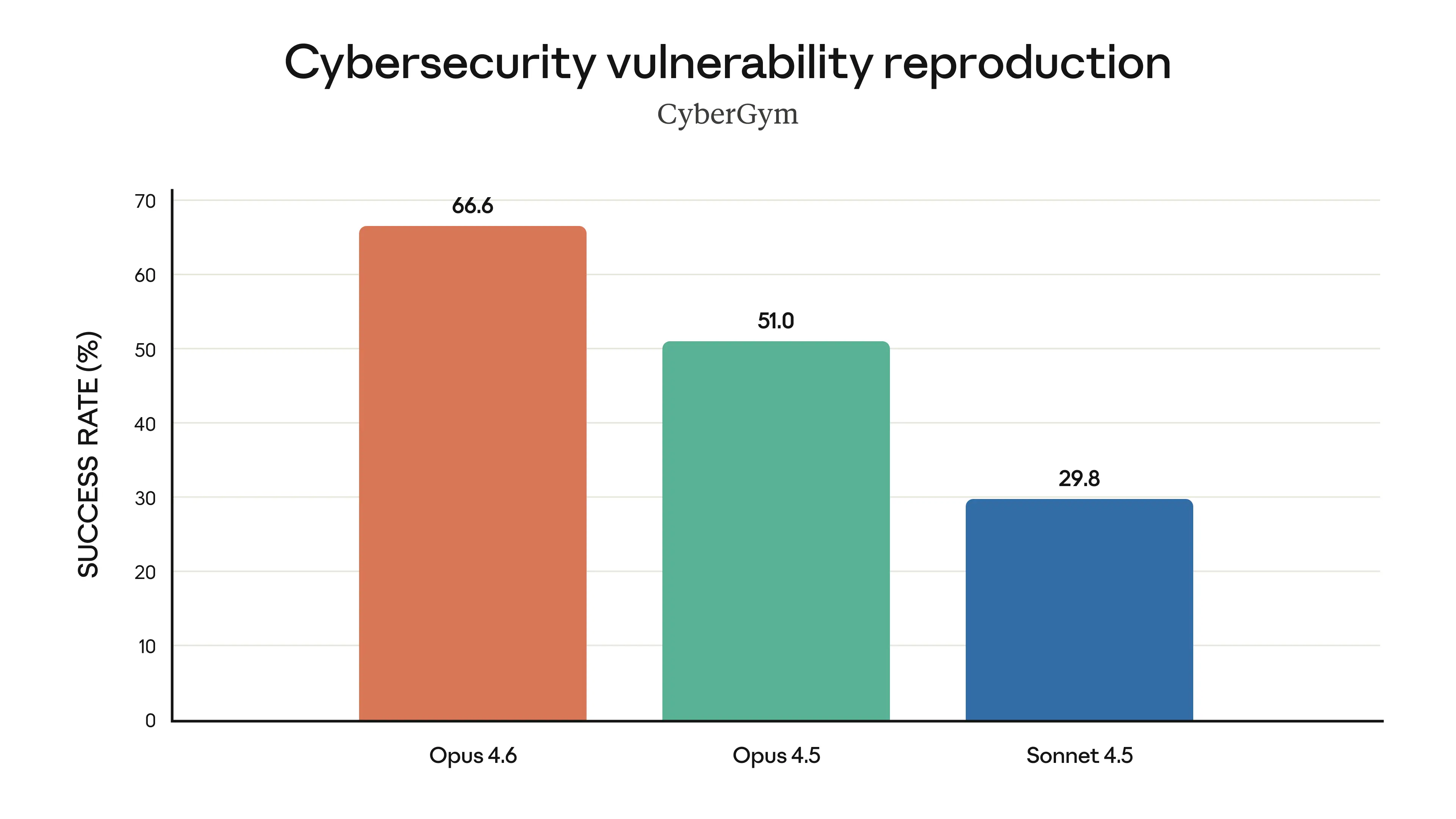 Claude Opus 4.6 CyberGym benchmark: finds real vulnerabilities better than any other model, Source: Anthropic
Claude Opus 4.6 CyberGym benchmark: finds real vulnerabilities better than any other model, Source: Anthropic
Pricing & Availability
This is perhaps the most important practical difference between the two models.
Verdict: Claude Opus 4.6 wins on accessibility. Full API access with transparent pricing ($5/$25 per million tokens) on day one, available on all three major cloud providers. GPT-5.3-Codex's lack of API access is a significant limitation for any use case beyond personal coding.
Ecosystem
Key difference: Claude Opus 4.6 benefits from Anthropic's Model Context Protocol (MCP) ecosystem, allowing integration with external tools, databases, and services. GPT-5.3-Codex operates within OpenAI's more closed ecosystem.
Verdict by Use Case
Here's the bottom line, which model to use for each scenario:
The Overall Picture
What About Cost?
Claude Opus 4.6 Cost Estimate
For a typical coding session (50K input tokens, 10K output tokens):
- →Standard: $0.25 input + $0.25 output = $0.50 per session
- →1M context: $0.50 input + $0.375 output = $0.875 per session
GPT-5.3-Codex Cost Estimate
- →Codex app: Included in ChatGPT Plus ($20/mo), unlimited within fair use
- →API: Not available, no per-token cost estimate possible
For heavy usage (50+ sessions/day), Opus 4.6 API costs can add up quickly. The ChatGPT subscription model with Codex may be more cost-effective for personal use, but cannot be integrated into products.
The Bigger Picture: February 2026 AI Landscape
These two releases confirm a clear industry trend: specialization.
- →OpenAI is building specialized models for specific domains (Codex for coding, future variants for other fields)
- →Anthropic is building general-purpose frontier models that excel across all domains while maintaining a single model line
This philosophical difference shapes everything:
- →OpenAI's approach: "Use the right tool for the job" (GPT-5.2 for general, Codex for coding)
- →Anthropic's approach: "One model to rule them all" (Opus 4.6 does everything)
Neither approach is inherently better. But for developers and enterprises, Anthropic's unified model simplifies architecture, one API, one billing, one integration for all tasks.
Test Your Knowledge
FAQ
Which model is better for beginners?
For beginners, GPT-5.3-Codex via the Codex app is more accessible, it provides interactive guidance, progress updates, and doesn't require API knowledge. Claude Opus 4.6 via claude.ai is also beginner-friendly but feels more like a traditional chat interface.
Can I use both models together?
Yes, and this is recommended for professional workflows. Use Claude Opus 4.6 as your primary model (API access, versatility, 1M context) and GPT-5.3-Codex via the Codex app for specialized coding sprints, security audits, and rapid prototyping.
Will GPT-5.3-Codex get API access?
OpenAI has confirmed they are "working to safely enable" API access. Given the model's "High" cybersecurity rating, additional safety measures are likely needed before broad programmatic access. No timeline has been announced.
How do these compare to Gemini?
Google's Gemini 3 Pro offers a 2M+ token context window (larger than both), but typically trails both Opus 4.6 and GPT-5.3-Codex on coding benchmarks. Gemini excels for massive document processing and Google Workspace integration.
Which model improves faster?
Based on historical patterns: OpenAI releases specialized Codex updates more frequently (every 1-2 months). Anthropic releases major Opus updates every 3-4 months but with larger jumps. Both are improving rapidly.
- →GPT-5.3 Codex Guide, Complete GPT-5.3-Codex analysis
- →Claude Opus 4.5 Guide, Previous Anthropic model
- →GPT-5.2 Codex Deep Dive, Previous OpenAI coding model
- →LLM Benchmarks 2026, Full model comparison
- →AI Code Editors Comparison, IDE and tool benchmarks
- →Claude Code vs Copilot vs Cursor, Coding tool comparison
Core Insights
- →
No universal winner, GPT-5.3-Codex leads on specialized coding and computer use; Claude Opus 4.6 leads on versatility, reasoning, and long context
- →
API access is the decisive practical difference, Only Opus 4.6 has it as of February 2026
- →
1M context vs. unknown, Opus 4.6's verified 1M context with 76% retrieval is a clear advantage for large-scale work
- →
Cybersecurity: both excel differently, GPT-5.3 is trained offensively; Opus 4.6 is defensive-focused
- →
Pricing favors Opus 4.6 for transparent, pay-per-use access ($5/$25 per million tokens)
- →
Use both for maximum capability, Opus for integration and versatility, Codex for specialized coding sprints
- →
The industry trend is clear: specialization (OpenAI) vs. generalization (Anthropic), your choice depends on whether you want one model or the best tool for each job
Understand AI Evaluation and Model Selection
Choosing between frontier AI models requires understanding benchmarks, limitations, and real-world performance. The data-driven approach in this article reflects the analytical skills you'll build in our advanced modules.
In our Module 8, AI Ethics & Safety, you'll learn:
- →How to evaluate AI models beyond marketing benchmarks
- →Understanding dual-use risks in cybersecurity AI
- →Building responsible AI deployment strategies
- →Bias detection and mitigation across models
- →When to trust AI-generated code in production
Module 8 — Ethics, Security & Compliance
Navigate AI risks, prompt injection, and responsible usage.
Dorian Laurenceau
Full-Stack Developer & Learning DesignerFull-stack web developer and learning designer. I spent 4 years as a freelance full-stack developer and 4 years teaching React, JavaScript, HTML/CSS and WordPress to adult learners. Today I design learning paths in web development and AI, grounded in learning science. I founded learn-prompting.fr to make AI practical and accessible, and built the Bluff app to gamify political transparency.
Weekly AI Insights
Tools, techniques & news — curated for AI practitioners. Free, no spam.
Free, no spam. Unsubscribe anytime.
→Related Articles
FAQ
Which is better, Claude Opus 4.6 or GPT-5.3-Codex?+
Neither is universally better. GPT-5.3-Codex leads on Terminal-Bench 2.0 (77.3%) and OSWorld (64.7%) for pure coding and computer use. Claude Opus 4.6 leads on general reasoning, offers 1M token context, has API access, and is more versatile for knowledge work.
Which model is better for coding in 2026?+
For pure agentic coding tasks, GPT-5.3-Codex scores higher on Terminal-Bench 2.0 (77.3% vs Opus 4.6's #1 ranking). For broader software engineering including architecture decisions and long-context work, Opus 4.6's 1M context and agent teams give it an edge.
How much do Claude Opus 4.6 and GPT-5.3 cost?+
Claude Opus 4.6: $5/$25 per million input/output tokens via API. GPT-5.3-Codex: no API pricing available yet, accessible only through paid ChatGPT plans ($20-200/month) and Codex tools.
Can I use Claude Opus 4.6 and GPT-5.3 via API?+
Claude Opus 4.6 has full API access from day one (Anthropic API, AWS Bedrock, Google Vertex AI). GPT-5.3-Codex does NOT have API access yet, OpenAI is 'working to safely enable' it.
Which model is safer for cybersecurity work?+
GPT-5.3-Codex is the first AI model rated 'High' in cybersecurity and is trained to find vulnerabilities. Claude Opus 4.6 won 38/40 cybersecurity investigations. Both excel but with different approaches: GPT is offensive-capable, Claude is defensive-focused.
Should I use Claude Opus 4.6 or GPT-5.3 for my startup?+
For startups, Claude Opus 4.6 is more practical today: API access for product integration, transparent pricing ($5/$25), 1M context for large codebases, and agent teams for parallel development. GPT-5.3-Codex lacks API access, limiting integration options.